The official Python site offers a good way to get started with the Python ecosystem and to learn Python, including a place to register for upcoming events, and documentation to get started.
RealPython dives into the different data types in Python in detail. Learn the difference between floating point and integers, what special characters can be used in Python and more.
This simple intro to Python scripts through the command line and text editors will get you up and running for your first Python experiments — a handy tool to get you started as you learn Python.
Codecademy offers a free interactive course that helps you practice the fundamentals of Python while giving you instant, game-like feedback. A great device for learning Python for those who like to practice their way to expertise.
The official Python development class from Google’s developers. This tutorial is a mix of interactive code snippets that can be copied and run on your end and contextual text. This is a semi-interactive way to learn Python from one of the world’s leading technology companies.
This interactive tutorial relies on live code snippets that can be implemented and practiced with. Use this resource as a way to learn interactively with a bit of guidance.
Want an easy, intuitive way to access and work with Python functions? Look no further than Jupyter Notebook. It’s much easier to work with than the command line and different cobbled together scripts. It’s the setup I use myself. This tutorial will help you get started on your path to learn Python.
W3Schools uses the same format they use to teach HTML and others with Python. Practice with interactive and text snippets for different basic functions. Use this tutorial to get a firm grounding in the language and to learn Python.
Kaggle is a platform which hosts data science and machine learning competitions. Competitors work with datasets and create as accurate of a predictive model as possible. They also offer interactive Python notebooks that help you learn the basics of Python. Choose the daily delivery option to have it become an email course instead.
This text-based tutorial aims to summarize all of the basic data and functional concepts in Python. It dives into the versatility of the language by focusing on the object and class portions of the object-oriented part of Python. By the end of it, you should have a neat summary of objects in Python as well as different data types and how to iterate or loop over them.
This simple tutorial on the official Python Wiki is chock-full of resources, and even includes a Chinese translation for non-English speakers looking to learn Python.
The Quora community is populated with many technologists that learn Python. This section devoted to Python includes running analysis and pressing questions on the state of Python and its practical application in all sorts of different fields, from data visualization to web development.
Dev.to has user-submitted articles and tutorials about Python from developers who are working with it every day. Use these perspectives to help you learn Python.
If you’re a fan of weekly newsletters that summarize the latest developments, news, and which curate interesting articles about Python, you’ll be in luck with Python Weekly. I’ve been a subscriber for many months, and I’ve always been pleased with the degree of effort and dedication placed towards highlighting exceptional resources.
Unlike the rest of the resources listed above, the Hitchhiker’s guide is much more opinionated and fixated on finding the best way to get set up with Python. Use it as a reference and a way to make sure you’re optimally set up to be using and learning Python.
edX uses corporate and academic partners to curate content about Python. The content is often free, but you will have to pay for a verified certificate showing that you have passed a course.
Coursera’s selection of Python courses can help you get access to credentials and courses from university and corporate providers. If you feel like you need some level of certification, similar to edX, Coursera offers a degree of curation and authentication that may suit those needs.
I learned how to clean and process data with the Pandas Cookbook. Working with it enabled me to clean data to the level that I needed in order to do machine learning and more.
It works through an example so you can learn how to filter through, group your data, and perform functions on it — then visualize the data as it needs be. The Pandas library is tailor-built to allow you to clean up data efficiently, and to work to transform it and see trends from an aggregate-level basis (with handy one-line functions such as head() or describe).
The Stack Overflow community is filled with pressing questions and tangible solutions. Use it a resource for implementation of Python and your path to learn Python.
I wrote this guide for The Next Web in order to distinguish between Python and R and their usages in the data science ecosystem. Since then, Python has pushed ever-forward and taken on many of the libraries that once formed the central basis of R’s strength in data analysis, visualization and exploration, while also welcoming in the cornerstone machine learning libraries that are driving the world. Still, it serves as a useful point of comparison and a list of resources for Python as well.
One essential skill when it comes to working with data is to access the APIs services like Twitter, Reddit and Facebook use to expose certain amounts of data they hold. This tutorial will help walk you through an example with the Reddit API and help you understand the different code responses you’ll get as you query an API.
Once you’re done crunching the data, you need to present it to get insights and share them with others. This guide to data visualization summarizes the data visualization options you have in Python including Pandas, Seaborn and a Python implementation of ggplot.
If you want a suite of options beyond Django to develop in Python and learn Python for web applications, look no further than this compilation. The Hacker Noon publication will often feature useful resources on Python outside of this article as well. It’s worth a follow.
This text-based tutorial helps introduce people to the basics of machine learning with Python. Towards Data Science, the Medium outlet with the article in question, is an excellent source for machine learning and data science resources.
The Machine Learning subreddit oftentimes focuses on the latest papers and empirical advances. Python implementations of those advances are discussed as well.
KDNuggets offers advanced content on data science, data analysis and machine learning. Its Python section deals with how to implement these ideas in Python.
Udemy offers a selection of Python courses, with many advanced options to teach you the intricacies of Python. These courses tend to be cheaper than the certified ones, though you’ll want to look carefully at the reviews.
This introduction to PySpark will help you get started with working with more advanced distributed file systems that allow you to deal and work with much larger datasets than is possible under a single system and Pandas.
The default way most data scientists use Python is to try out model ideas with scikit-learn: a simple, optimized implementation of different machine learning models. Learn a bit of machine learning theory then implement and practice with the scikit-learn framework.
This tutorial walks through more advanced versions of data visualizations and how to implement them, allowing you to take a preview of different advanced ways you can slice your data from correlation heatmaps to scatterplot matricies.
Coursera’s selection of courses on machine learning with Python are veryw well-known. This introduction offered with IBM helps to walk you through videos and explanations of machine learning concepts.
Deeplearning.ai is Andrew Ng’s (the famous Stanford professor in AI and founder of Coursera) attempt to bring deep learning to the masses. I ended up finishing all of the courses: they offer certification and are a refreshing mix of both interactive notebooks where you can work with the different concepts and videos from Andrew Ng himself.
This curated course on deep learning helps break down section-by-section aspects of machine learning. Best of all, it’s completely free. I often use fast.ai as a refresher or a deep dive into a deep learning idea I don’t quite understand.
This tutorial helps you use the high-level Keras component of TensorFlow and Google cloud infrastructure to do deep learning on a set of fashion images. It’s a great way to learn and practice your deep learning skills.
Kaggle offers a variety of datasets with user examples and upvoting to guide you to the most popular datasets. Use the examples and datasets to create your own data analysis, visualization, or machine learning model.
Practice Python has a bunch of beginner exercises that can help you ease into using Python and practicing it. Use this as an initial warmup exercise before you tackle different projects and exercises.
The Python exercises on W3Schools follow the sections in their tutorials, and allow you to get some interactive practice with Python (though the exercises are in practice very simple).
HackerRank offers a bunch of exercises that require you to solve without any context. It’s the best way to practice different functions and outputs in Python in isolation (though you’ll still want to do different projects to be able to cement your Python skill.) You’ll earn points and badges as you complete more challenges. This certainly motivates me to learn more. A very useful sandbox for you to learn Python with.
Project Euler offers a variety of ever-harder programming challenges that aim to test whether you can solve mathematical problems with Python. Use it to practice your mathematical reasoning and your Pythonic abilities.
This documentation helps you get on the ground with your first Django app, allowing you to use Python to get something up on the web. Once you’ve started with it, you can build anything you want.
Should you ever be in an interview where your Python skills are at question, this list of interview questions will help as a useful reminder and refresher and a good way for you to practice and cement different Python concepts.
Ethical hackers play an important role in organizations by finding and fixing vulnerabilities in systems and applications. Python is a high-level programming language that’s ideal for security professionals as it’s easy to learn and lets you create functional programs with a limited amount of code.
]]><p>Python是著名的“龟叔”Guido van Rossum在1989年圣诞节期间,为了打发无聊的圣诞节而编写的一个编程语言。Python就为我们提供了非常完善的基础代码库,覆盖了网络、文件、GUI、数据库、文本等大量内容,被形象地称作“内置电池(batteries included)”。用Python开发,许多功能不必从零编写,直接使用现成的即可。除了内置的库外,Python还有大量的第三方库,也就是别人开发的,供你直接使用的东西。当然,如果你开发的代码通过很好的封装,也可以作为第三方库给别人使用。</p>科技论文词汇与语法http://saili.science/vocabulary/2019-05-05T03:03:27.000Z2019-05-05T03:17:19.000Z虽然大家的学科领域不同,但起承转合的论文写作逻辑套路是共通的,掌握了这些高频词汇和短语,了解了提示文章逻辑的连接词,又掌握了文章论述中惯用的表达方式,一定能帮您在SCI论文写作过程中更轻松容易,提高写作效率。
i.e.是id est(“that is” , "in other words"。进一步解释用,意为:也就是)的缩写。目的是用来进一步解释前面所说的观点(不像后文的e.g.那样引入实例来形象化),意思是“那就是说,换句话说”。它后面最好紧跟着一个逗号,再跟一个解释。(看大量例句,发现有些句子的确省略了逗号,见例句1和例句2)
例句1:Each of these items are actionable, i. e. you can actually do them. 例句2:The film is only open to adults, i.e. people over 18. 例句3:And you have to cross reference this time/effort analysis to the results (i.e., the bugs) that the effort yielded.
e.g.是exempli gratia("for example; for instance;such as"。举例用,意为:例如)的缩写,其目的用若干例子来让前面说法更具体,更易感知。在使用中,最好把e.g.连同它的例子放在括号中,如例句2。
例句1: I like sports, e.g., football. 例句2:I like most of sports activities (e.g., football).
i.e.和e.g.的区别:
例句1:I like to eat boardwalk food, i.e., funnel cake and french fries. 例句2:I like to eat boardwalk food, e.g., funnel cake and french fries.
例句1表示只有 funnel cake and french fries这两种boardwalk食物,而且这两种我都喜欢。例句2表示我喜欢boardwalk食物,比如 funnel cake and french fries;但是诸如snow cones and corn dogs等其他类型,我也可能喜欢。
etc.是et cetera(“and so forth; and the others; and other things; and the rest; and so on"。举例用,意为:等等)的缩写。它放在列表的最后,表示前面的例子还没列举完,最后加个词“等等”。
etc.前面要有逗号。一般不要在e.g.的列表最后用etc( 在including后的列表后也不宜使用etc)。这是因为 e.g. 表示泛泛的举几个例子,并没有囊括所有的实例,其中就已经包含“等等”,如果再加一个 etc. 就多余了。
例句1: I need to go to the store and buy some pie, milk, cheese, etc.
viz.是videlicet( "namely", "towit", "precisely", "that is to say"。进一步解释用,意为:即)的缩写,与e.g.不同,viz位于同位列表之前,要把它前面单词所包含的项目全部列出。
例句1:The school offers two modules in Teaching English as a Foreign Language, viz. Principles and Methods of Language Teaching and Applied Linguistics.(该校提供两个模块用于英语作为外语的教学,即语言教学的原理方法和应用语言学。) 例句2: In this paper, a new TDNN architecture with two input variable, viz. wave form and its phase difference, is developed to reduce the grain noise.(本文提出了一种新的TDNN结构用于降低粗晶材料结构噪声,该结构具有波形及其相位差组成的双变量输入。)
et al.是et alia("and others; and co-workers"。在引用文献作者时用,意为:等其他人)的缩写。它几乎都是在列文献作者时使用,即把主要作者列出后,其它作者全放在et al. 里面。
et al.的前面不要逗号。人的场合用et al,而无生命的场合用etc.(et cetera)。
例句1: These results agree with the ones published by Pelon et al. (2002). 例句2: Clegg et al. (1995) explain that in the electronics industry linear-programming models can be used to analyse the viability of the recovered parts in remanufacturing.(克莱格等人(1995)解释说,电子行业的线性规划模型可以用来分析在再制造过程中回收零部件的可行性。)
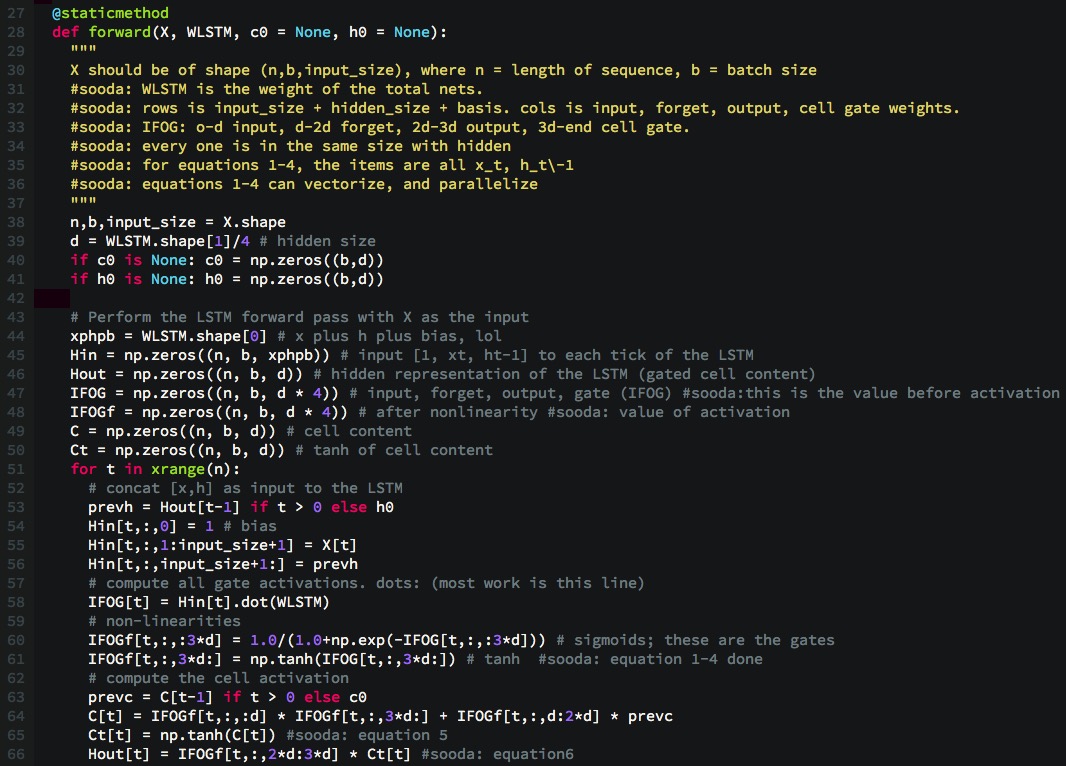
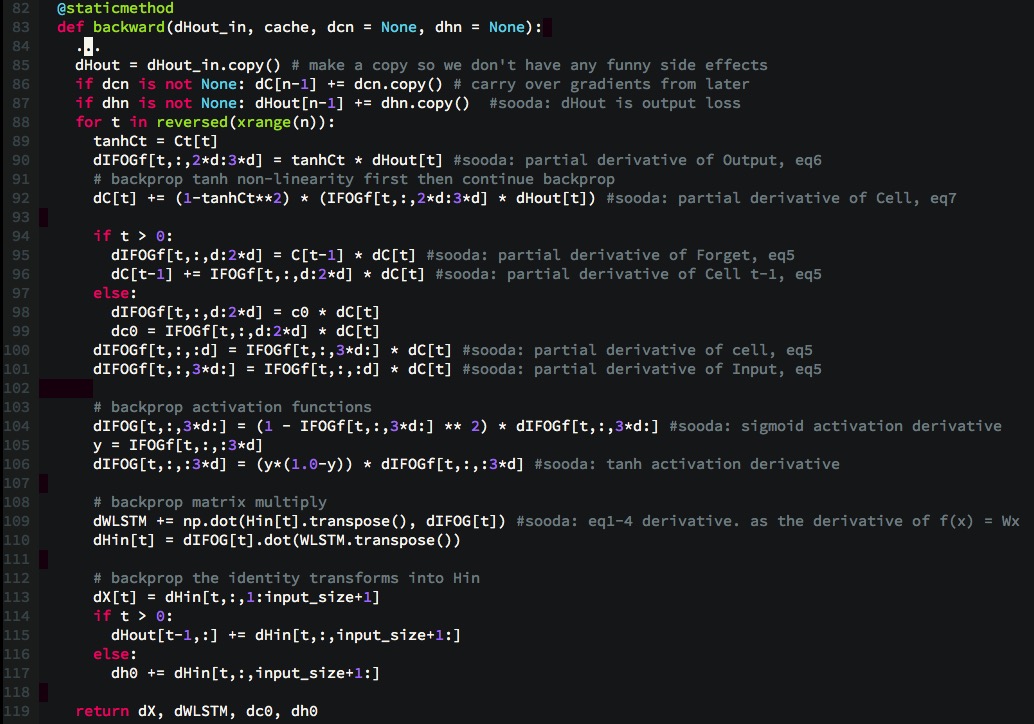
Gama J, Žliobaitė I, Bifet A, et al. A survey on concept drift adaptation[J]. ACM computing surveys (CSUR), 2014, 46(4): 44. Shalev-Shwartz S. Online learning and online convex optimization[J]. Foundations and Trends® in Machine Learning, 2012, 4(2): 107-194. Žliobaitė I, Pechenizkiy M, Gama J. An overview of concept drift applications[M]//Big data analysis: new algorithms for a new society. Springer, Cham, 2016: 91-114.
We can distinguish two learning modes: offline learning and online learning.
I.I. 离线学习
In offline learning the whole training data must be available at the time of model training. Only when training is completed the model can be used for predicting.
initialize all weights to random value repeat: for t in training_set: compute train_error for t adjust weights base on train_error until error rate is very small or error rate variation stops
优点:
消除样本顺序的影响
对梯度向量的精确估计,因此,在简单条件下,保证了这一方法最速下降到局部极小点的收敛性。
学习的并行性。
缺点:
有着存储需求
I.II. 在线学习
不同理解方式:
online and batch learning:在线算法按照顺序处理数据,一个数据点训练完了直接更新权重。它们产生一个模型,并在把这个模型放入实际操作中,而不需要在一开始就提供完整的训练数据集。随着更多的实时数据到达,模型会在操作中不断地更新。In contrast, online algorithms process data sequentially. They produce a model and put it in operation without having the complete training data set available at the beginning. The model is continuously updated during operation as more training data arrives. Less restrictive than online algorithms are incremental algorithms that process input examples one by one (or batch by batch) and update the decision model after receiving each example. Incremental algorithms may have random access to previous examples or representative/selected examples. In such a case, these algorithms are called incremental algorithms with partial memory. Typically, in incremental algorithms, for any new presentation of data, the update operation of the model is based on the previous one. Streaming algorithms are online algorithms for processing high-speed continuous flows of data. In streaming, examples are processed sequentially as well and can be examined in only a few passes (typically just one). These algorithms use limited memory and limited processing time per item.
initialize all weights to random value for t in training_set: repeat: compute train_error for t adjust weights base on train_error until error rate is very small or error rate variation stops
decremental learning,即抛弃“价值最低”的保留的训练样本。这两个概念在incremental and decremental svm这篇论文里面可以看到具体的操作过程。
Cauwenberghs G, Poggio T. Incremental and decremental support vector machine learning[C]//Advances in neural information processing systems. 2001: 409-415. Gâlmeanu H, Andonie R. Implementation issues of an incremental and decremental SVM[C]//International Conference on Artificial Neural Networks. Springer, Berlin, Heidelberg, 2008: 325-335.
]]><p>机器学习算法可以分成两类。离线学习和在线学习。在线机器学习指每次通过一个训练实例学习模型的学习方法。</p>协方差矩阵http://saili.science/covariance/2018-07-19T13:39:13.000Z2024-04-10T13:10:52.000Z在统计学与概率论中,协方差矩阵(也称离差矩阵、方差-协方差矩阵)是一个矩阵,其 i, j 位置的元素是第 i 个与第 j 个随机向量(即随机变量构成的向量)之间的协方差。这是从标量随机变量到高维度随机向量的自然推广。
% 方法二 % 先让样本矩阵中心化,即每一维度减去该维度的均值,使每一维度上的均值为0 % 然后直接用新的到的样本矩阵乘上它的转置,然后除以(N-1)即可。 X = MySample - repmat(mean(MySample),10,1); % 中心化样本矩阵,使各维度均值为0 C = (X'*X)./(size(X,1)-1);
% 方法三 cov(MySample)
]]><p>在统计学与概率论中,协方差矩阵(也称离差矩阵、方差-协方差矩阵)是一个矩阵,其 i, j 位置的元素是第 i 个与第 j 个随机向量(即随机变量构成的向量)之间的协方差。这是从标量随机变量到高维度随机向量的自然推广。</p>数据处理http://saili.science/data-process/2018-07-14T13:24:58.000Z2018-08-13T07:03:04.000Z如果把重点放在数据的处理方式上,那么长期共存的方式大概有两种:
Hinge Loss/多分类 SVM 损失:简言之,在一定的安全间隔内(通常是 1),正确类别的分数应高于所有错误类别的分数之和。因此 hinge loss 常用于最大间隔分类(maximum-margin classification),最常用的是支持向量机。尽管不可微,但它是一个凸函数,因此可以轻而易举地使用机器学习领域中常用的凸优化器。
Support Vector Regression, which evolved from the support vector classification for doing regression tasks by introduction of the \(\varepsilon\)-insensitive loss function, is a data-driven machine learning methodology.
The parameter \(C\) controls the trade-off between the complexity of the function and the frequency in which errors are allowed. The parameter \(\sigma\) affects the mapping transformation of the input data to the feature space and controls the complexity of the model, thus, it is important to select suitable parameters, and the value of parameter \(\sigma\) should be selected more carefully than \(C\) .
Li, S., Fang, H. & Liu, X., 2018. Parameter optimization of support vector regression based on sine cosine algorithm. Expert Systems with Applications, 91, pp.63–77. Available at: http://dx.doi.org/10.1016/j.eswa.2017.08.038.
Li, S., Fang, H., 2017. A WOA-based algorithm for parameter optimization of support vector regression and its application to condition prognostics. 2017 36th Chinese Control Conference (CCC). Available at: http://dx.doi.org/10.23919/chicc.2017.8028516.
]]><p>在机器学习和认知科学领域,人工神经网络(英文:artificial neural network,缩写ANN),简称神经网络(英文:neural network,缩写NN)或类神经网络,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。现代神经网络是一种非线性统计性数据建模工具。</p>如何理解HTTPShttp://saili.science/https/2018-01-20T14:17:08.000Z2018-03-23T12:25:03.000Z超文本传输安全协议(英语:Hypertext Transfer Protocol Secure,缩写:HTTPS,常称为HTTP over TLS,HTTP over SSL或HTTP Secure)是一种通过计算机网络进行安全通信的传输协议。HTTPS经由HTTP进行通信,但利用SSL/TLS来加密数据包。HTTPS开发的主要目的,是提供对网站服务器的身份认证,保护交换数据的隐私与完整性。这个协议由网景公司(Netscape)在1994年首次提出,随后扩展到互联网上。
]]><p>超文本传输安全协议(英语:Hypertext Transfer Protocol Secure,缩写:HTTPS,常称为HTTP over TLS,HTTP over SSL或HTTP Secure)是一种通过计算机网络进行安全通信的传输协议。HTTPS经由HTTP进行通信,但利用SSL/TLS来加密数据包。HTTPS开发的主要目的,是提供对网站服务器的身份认证,保护交换数据的隐私与完整性。这个协议由网景公司(Netscape)在1994年首次提出,随后扩展到互联网上。</p>区块链http://saili.science/blockchain/2018-01-20T10:12:44.000Z2018-03-23T12:25:03.000Z区块链(英语:blockchain 或 block chain)是用分布式数据库识别、传播和记载信息的智能化对等网络, 也称为价值互联网。中本聪在2008年,于《比特币白皮书》中提出“区块链”概念,并在2009年创立了比特币社会网络,开发出第一个区块,即“创世区块”。本文根据阮一峰老师的区块链入门教程整理并解释一下区块链到底是什么,有何特别之处。