深度学习
机器学习中提到了人工神经网络 (ANN),它也可以分为两个类型:第一类是浅层的网络。如早期的感知机,它只有一个输入层和输出层组成。另外,上面提到的推断统计类型的机器学习方法从广义上说基本都可以归到这一类。第二类就是深层的网络,即深度神经网络,可以成为深度学习网络。它除了输出层和输出层之外,还有一个或多个隐层,并且通过学习算法,在隐层实现了对数据的抽象表达,如同人的认知系统。我们暂且对机器学习、深度学习的关系做一个简单粗暴的总结,那就是:机器学习中的人工神经网络是深度学习的起源,基于神经网络芯片的、大数据的、多层次的学习叫深度学习。
深度学习(英语:deep learning)是机器学习拉出的分支,它试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法。深度学习是机器学习中一种基于对数据进行表征学习的方法。观测值(例如一幅图像)可以使用多种方式来表示,如每个像素强度值的向量,或者更抽象地表示成一系列边、特定形状的区域等。而使用某些特定的表示方法更容易从实例中学习任务(例如,人脸识别或面部表情识别)。
如果更系统一点,可以把当今流行的深度神经网络分为应对具有空间性分布数据的CNN(卷积神经网络,Convolutional Neural Network)和应对具有时间性分布数据的RNN(递归神经网络(又称循环神经网络),Recursive Neural Network)。CNN往往应用于图像识别,RNN往往应用于语音识别和自然语言处理。语音和语言是一种按时间分布的数据,也就是说下一句的意义和上一句有关联,这跟RNN网络可以记住历史信息的特性有关系。
- 机器学习与深度学习资料汇总
- Awesome Deep Learning
- Qix仓库提供了机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 1),机器学习(Machine Learning)&深度学习(Deep Learning)资料
- DeepLearningBook读书笔记
- Deep Learning Mindmap / Cheatsheet
- 零基础入门深度学习
- A Primer on Deep Learning 描述了深度学习与无监督学习,神经网络之间的关系与区别
I. 逻辑框架
THE NEURAL NETWORK ZOO展示了最流行的神经网络变体:
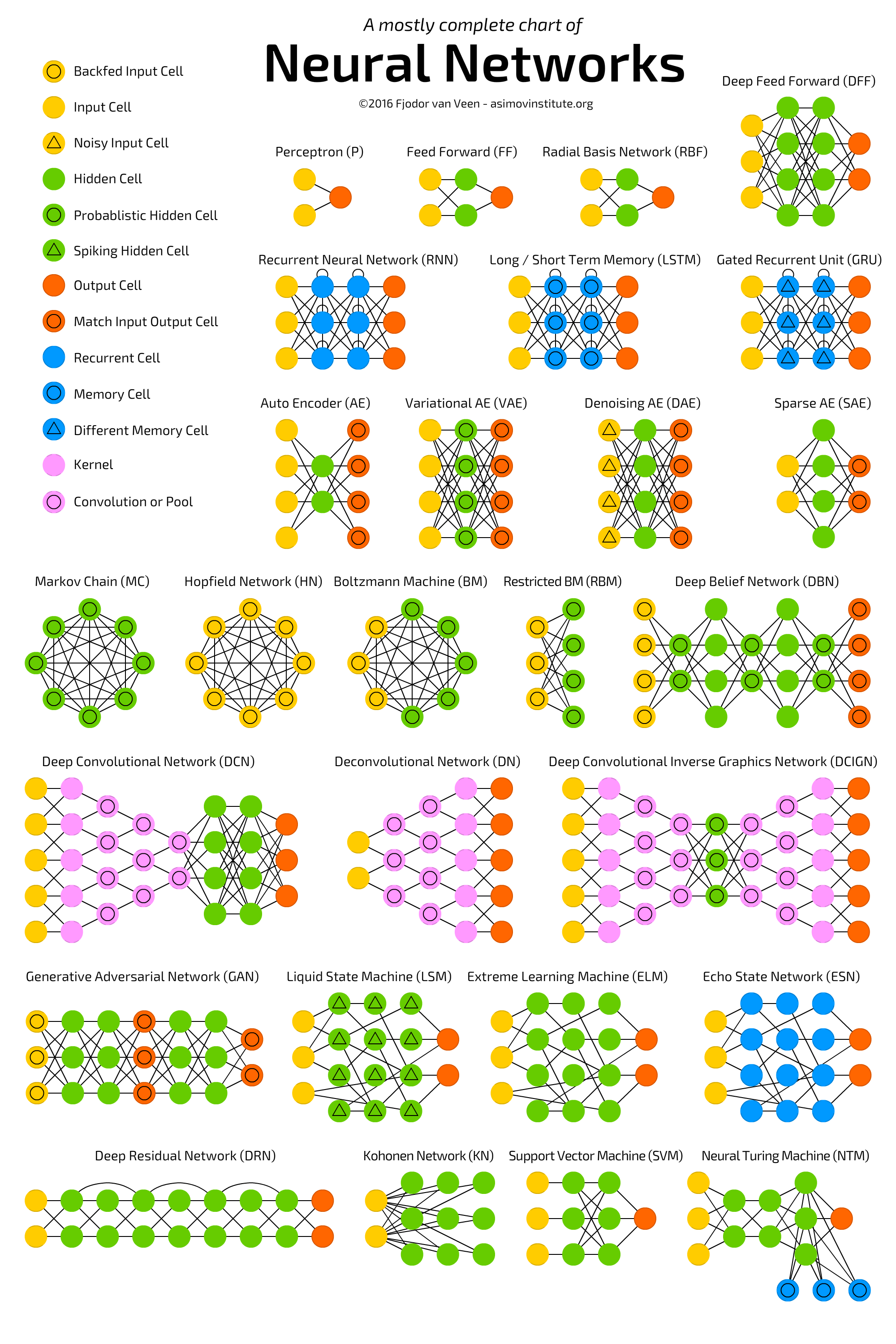
神经网络有一个独特的能力,被称作「泛逼近函数」(Universal Approximation function),所以神经网络的拓扑和结构变体是很多样化的。这本身就是一个很大的话题,Michael Nielsen 在文章中做了详细的描述。读完这个我们可以相信:神经网络可以模拟任何函数,不管它是多么的复杂。上面提到的神经网络也被称为前馈神经网络(FFNN),因为信息流是单向、无环的。现在我们已经理解了感知机和前馈神经网络的基本知识,我们可以想象,数百个输入连接到数个这样的隐藏层会形成一个复杂的神经网络,通常被称为深度神经网络或者深度前馈神经网络(DFF)。
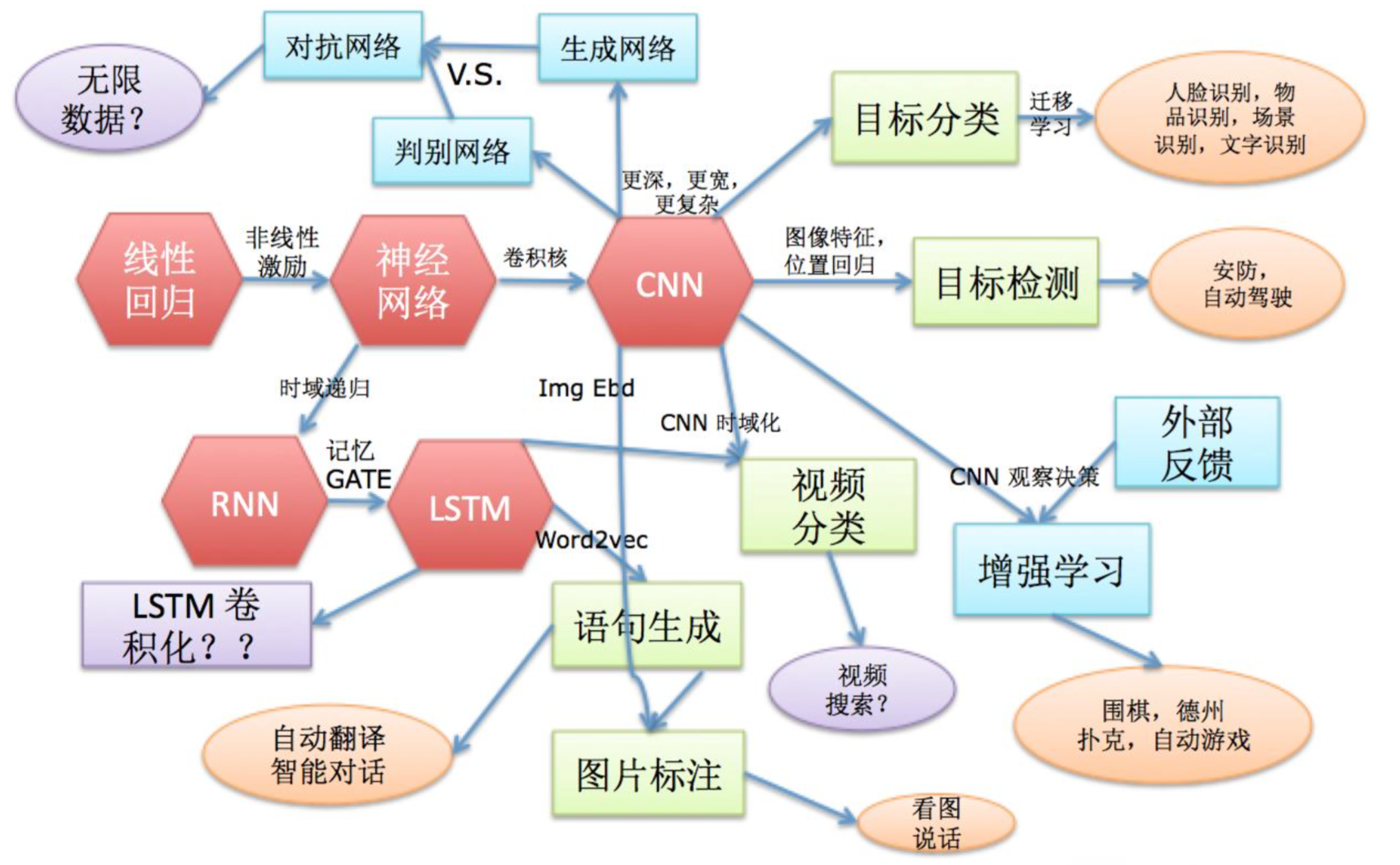
线性回归 (+ 非线性激励) → 神经网络
- 有线性映射关系的数据,找到映射关系,非常简单,只能描述简单的映射关系
- 大部分关系是非线性的,所以改进方法就是加一个非线性激励,某种程度是一个 NORMALIZE,但是是非线性的,对参数有更强的描述能力
- +非线性激励,描述稍微复杂的映射关系,形成神经网络
- 神经网络输入是 1 维信息,普通网络之间进行的是代数运算,然后经过非线性激励,形成新的神经网络
神经网络 (+时域递归) → RNN
- 神经网络处理一维信息,然而一维信息很可能是有前后的时间联系的,如人的语音,前面说的话与后面是有联系的,RNN 学习前后关系
- 相当于某一刻的输出同时也作为下一刻的输入,所以这一刻的输入不仅是这一刻的输入+上一刻输出的信息
RNN (+记忆GATE) → LSTM
- RNN 只考虑前一刻信息,Tn 时刻只考虑 Tn-1 的,那么 Tn-2,就是 Tn-2 → Tn-1 → Tn 逐层衰减,信息也会越来越弱
- 如果很久之前的记忆很重要,要把它记下来,就相当于有一个记忆方程,那么就可以用 LSTM,实现长记忆短记忆
- Gate 来分析哪一部分存储,哪一部分进行传递
- 应用: 语句生成 → 自动翻译智能对话
神经网络 (+卷积核) → CNN
- 基本的代数运算用卷积核来代替。一维到二维甚至是三维的转化,相当于一个空间上的扩展
- 应用: 图片分类 → 目标分类(人脸识别/物品识别/场景识别/文字识别)、目标检测(安防/自动驾驶)
- 深度,宽度,递归的变化
增加深度(网络层数),E.g.OverFeat-accurate,VGG
增加宽度(filter数),E.g.zf-big,OverFeat-accurate
递归的变化,可以跳过下一层,传到后面几层 - 结构与性能
- 特定问题的具体结构
比如说人脸识别,我们知道人脸有大体结构,用 CNN 来做识别时,可以让不同位置的像素不共享参数,眼睛有处理眼睛部分的卷积核,鼻子有处理鼻子部分的卷积核,它们之间不共享参数,这样的话参数会很多,但这样训练的结果可能会更好一些,专门对眼睛/鼻子进行训练
LSTM 卷积化(LSTM + CNN)
- 应用: 产生理解图片的语言 → 图片描述/标注 → 看图说话,时域的图片 → 视频分类 → 视频搜索
- NLP 方向比较成熟的只有语音识别,语义挖掘方面还是目前的热点
外部反馈 → 增强学习
- 模仿人类学习的模型
- CNN 能理解,把它放在游戏中,做决策,给出反馈,让它学会决策的能力
- 应用: 围棋,德州扑克,自动游戏,路径规划
生成网络 + 判别网络 → 对抗网络
- 生成网络学会怎么生成数据,如输入有表情图片,学习怎么输出没有表情的图片,实际生成质量不是很好
- 判别网络判断生成网络生成的图片是不是真的
- 两者结合生成网络生成的图片越来越逼真,判别网络鉴别图片的能力也越来越强
- 作用: 生成数据,相当于无监督学习
II. 卷积神经网络CNN
自 2012 年以来所有获得 ImageNet 竞赛冠军的 CNN 模型
一文看懂卷积神经网络
图解CNN:通过100张图一步步理解CNN
CNN 由三种不同的层组成,即「卷积层」、「池化层」、「密集层或全连接层」。我们之前的神经网络都是典型的全连接层神经网络。如果想了解更多卷积和池化层的知识,可以阅读 Andrej Karpathy 的解释。
卷积神经网络采用的四种基本组件1:Pooling、Dropouts、Batch Normalization、Data Augmentation 。
- Pooling是一种矢量,对图像的每个局部区域进行标量变换,就像卷积操作一样。Pooling的想法看起来可能适得其反,因为它会导致信息的丢失,但它在实践中证明是非常有效的。
- Dropouts是一种抑制过度拟合的技巧。 它可以随机地将一些激活值设置为0,从而避免过度拟合。
- 批量标准化(Batch Normalization)的工作原理是将每一批图像都标准化,从而得到零均值和单位方差,避免出现梯度消失。
- 随机扭曲训练图像,使用水平切除,垂直切除,旋转,增白,移位和其他扭曲的手段。这将使covnets学会如何处理这种扭曲,因此,他们将能够在现实世界中很好地工作。
III. 递归神经网络RNN
循环神经网络RNN以及LSTM的推导和实现
RNN模型
详解循环神经网络(Recurrent Neural Network)
III.I. LSTM
Alex Graves RNN以及LSTM的介绍和公式梳理
零基础入门深度学习(6) - 长短时记忆网络(LSTM)
循环神经网络RNN以及LSTM的推导和实现
LSTM模型理论总结(产生、发展和性能等)
LSTM的公式推导详解
LSTM(without Peephole)参数更新公式推导
RNN以及LSTM的介绍和公式梳理
Understanding LSTM Networks(中文)
Exploring LSTMs(中文)
Chapter 10.1: DeepNLP — LSTM (Long Short Term Memory) Networks with Math
A Beginner’s Guide to Recurrent Networks and LSTMs
长短期记忆递归神经网络LSTM是为了缓解RNN的梯度弥散问题而提出的一种变种模型,之所以能够缓解这个问题,是因为在原始的RNN中,梯度的传递是乘法的过程,如果梯度很小,那么从T时刻传递到后面的梯度只会越来越小,甚至消失,在优化空间中相当于一部分参数进行更新,而另外一部分参数几乎不变,那么问题的较优解也就很难收敛到。而LSTM通过推导会发现,梯度是以一种累加的方式进行反向传递的,从而一定程度上客服了累乘导致的梯度弥散的问题。
III.I.I. LSTM的时序应用
A Guide For Time Series Prediction Using Recurrent Neural Networks (LSTMs)
LSTM的时序应用
Python中利用LSTM模型进行时间序列预测分析
Time Series Forecasting with the Long Short-Term Memory Network in Python
Long short-term memory (LSTM) layer in MATLAB R2017B
深度学习-LSTM网络-代码-示例
LSTM简单例子(MATLAB code):1,2
IV. CNN+RNN
相同点:
- 都是传统神经网络的扩展;
- 前向计算产生结果,反向计算进行模型的更新;
- 每层神经网络横向可以多个神经元共存,纵向可以有多层神经网络连接。
不同点:
- CNN进行空间扩展,神经元与特征卷积;RNN进行时间扩展,神经元与多个时间输出计算;
- RNN可以用于描述时间上连续状态的输出,有记忆功能;CNN则用于静态输出;
- CNN高级结构可以达到100+深度;RNN的深度有限。
组合的意义:
- 大量信息同时具有时间空间特性:视频,图文结合,真实的场景对话;
- 带有图像的对话,文本表达更具体;
- 视频相对图片描述的内容更完整。
组合方式:
- CNN特征提取,用于RNN语句生成->图片标注
- RNN特征提取用于CNN内容分类->视频分类
- CNN特征提取用于对话问答->图片问答
V. 生成对抗网络GAN
GAN是“生成对抗网络”(Generative Adversarial Networks)的简称,由2014年还在蒙特利尔读博士的Ian Goodfellow引入深度学习领域。2016年,GAN热潮席卷AI领域顶级会议,从ICLR到NIPS,大量高质量论文被发表和探讨。Yann LeCun曾评价GAN是“20年来机器学习领域最酷的想法”。
VI. 训练
深度神经网络训练的必知技巧主要介绍8种实现细节的技巧或tricks:数据增广、图像预处理、网络初始化、训练过程中的技巧、激活函数的选择、不同正则化方法、来自于数据的洞察、集成多个深度网络的方法。
VII. 实现
- Which GPU(s) to Get for Deep Learning: My Experience and Advice for Using GPUs in Deep Learning 文章建议用GPU实现深度学习,并提供了GPU选择的参考意见
VIII. 开源的项目
- 开源的框架及工具
- Tensorflow
- Torch
- 采用LuaJIT实现,提供了C接口
- 支持IOS和Android
- 源代码
- Theano
- 一个python库,方便多维度的数学计算,在学术研究中经常使用
- Montreal大学的深度学习课程就用到了它
- 在深度学习上的应用案例
- 详细介绍
- 源代码
- Deprecation
- Matlab实现
- 目前已停止维护,如果需要用Matlab做项目的话,可以参考。
- 源代码
- 其他应用
IX. Q&A
深度学习大多数都是用gpu做,我看文献说速度可能会差10倍。如果是只用cpu来实现是否可行?
- 只用CPU来实现深度学习是可以的,只是需要的时间特别的长,对CPU的要求也很高,笔记本电脑和普通的台式机的都不太适合,一般都是推荐用大型的服务器或者云服务。
- 深度学习相比SVM来说,需要更多层的计算,运算量比较大。 一般来说,用GPU来实现深度学习,速度会比cpu高5倍,而且数据量越大,GPU的优势越明显,最大能达到10倍的差距,所以,大量的文献资料是建议用GPU来进行处理的,毕竟现在GPU的性能也越来越高,而且并行计算的能力也越来越好。
- 至于在实际应用中,是否只用CPU来实现,这个还是要具体问题具体分析了,没有一个统一的标准答案。主要根据以下几个方面来考虑,问题域应用的硬件环境,要处理的数据量的多少,结果的准确性要求,输入到输出的时间限制。如果数据量大,需要快速有结果的话,不建议只用CPU来实现。(ps,学术研究的话,不建议只用CPU实现,因为算法的计算量摆在那里的,在论文中说是只用CPU实现的话,估计论文不太好发。实在是要只用CPU实现的话,可以考虑结合分布式的并行计算,云计算,云存储之类的技术。)
深度学习是否也要事先定义一些特征呢?我看到有的文章是不需要定义特征的,深度学习方法可以自学习一些特征来进行。而有一些文章却自己定义了一些特征,如果自己定义特征,深度学习方法和普通机器学习方法有差别吗?而且如何选特征选多少特征会比较合适呢?
- 深度学习实质是构建具有很多隐层的机器学习模型,再通过海量的数据来进行训练,得出更有用的特征,再根据这些特征进行分类或者预测。所以,不需要事先定义特征。但是,如果训练的数据量小的话,其自学习到的特征便不准确,导致最后的分类结果出现很大的误差。所以,理论上来说,深度学习算法是不需要自定义的特征的,但是在某些环境中,加入自定义的特征能更好的提高算法的精确度。
- 普通的机器学习方法是浅层学习,而深度学习的不同在于:1)强调了模型结构的深度,通常有5层、6层,甚至10多层的隐层节点;2)明确突出了特征学习的重要性,也就是说,通过逐层特征变换,将样本在原空间的特征表示变换到一个新特征空间,从而使分类或预测更加容易。但是,与自己定义特征的方法相比,深度学习利用大数据来自学习特征,更能够刻画数据的内在信息,特征提取也更加的客观。
- 深度学习的训练过程如下:
- 1)使用自下上升非监督学习(就是从底层开始,一层一层的往顶层训练):
采用无标定数据(有标定数据也可)分层训练各层参数,这一步可以看作是一个无监督训练过程,是和传统神经网络区别最大的部分(这个过程可以看作是feature learning过程):
具体的,先用无标定数据训练第一层,训练时先学习第一层的参数(这一层可以看作是得到一个使得输出和输入差别最小的三层神经网络的隐层),由于模型capacity的限制以及稀疏性约束,使得得到的模型能够学习到数据本身的结构,从而得到比输入更具有表示能力的特征;在学习得到第n-1层后,将n-1层的输出作为第n层的输入,训练第n层,由此分别得到各层的参数;
- 2)自顶向下的监督学习(就是通过带标签的数据去训练,误差自顶向下传输,对网络进行微调):
- 基于第一步得到的各层参数进一步fine-tune整个多层模型的参数,这一步是一个有监督训练过程;第一步类似神经网络的随机初始化初值过程,由于DL的第一步不是随机初始化,而是通过学习输入数据的结构得到的,因而这个初值更接近全局最优,从而能够取得更好的效果;所以deep learning效果好很大程度上归功于第一步的feature learning过程。
- 1)使用自下上升非监督学习(就是从底层开始,一层一层的往顶层训练):
- 如何选特征,选多少特征这个需要具体问题具体分析。任何一种方法,特征越多,给出的参考信息就越多,准确性会得到提升。但特征多意味着计算复杂,探索的空间大,可以用来训练的数据在每个特征上就会稀疏,都会带来各种问题,并不一定特征越多越好。
对服务器和样本量有什么要求?对训练集的数目有要求吗?如果像题2那样可以自己定义特征的话,特征的数目和训练集的数目有什么有什么要求吗?
- 服务器的要求:
- GPU:GTX 680 或者GTX 960(这是穷人配置);GTX 980 (表现最佳,强烈推荐)
- CPU配置:Intel系列,高端的即可,做好多核
- 内存:越大越好,至少要和GPU的内存一样大
- 训练的数目问题,深度学习的应用主要是大数据,解决的是普通的机器学习算法处理大数据时的特征提取问题,结果准确性,结果生成速度等问题,如果数据量太少的话,深度学习算法反而在性能上还比不上普通的机器学习算法。所以,训练的数据越多越好。至于特征的数目,这个要具体问题具体分析了,目前没有统一的标准和理论依据,只能凭经验或者在试验中不断调整测试。
- 服务器的要求:
深度学习的几种模型如(AutoEncoder,Sparse Coding,Restricted Boltzmann Machine,Deep BeliefNetworks,Convolutional Neural Networks)在解决实际问题的时候是否有倾向性的解决某一类问题?比如说更倾向解决分类问题还是预测连续值的问题?或者说在效能上有什么差别(如时间或者空间,或者准确度上)?
- AutoEncoder自动编码器,可用于分类问题;
- Sparse Coding稀疏编码算法是一种无监督学习方法;主要应用于图像处理和语音信号处理
- Restricted Boltzmann Machine (RBM)限制波尔兹曼机,受限制玻尔兹曼机在降维、分类、协同过滤、特征学习和主题建模中得到了应用。
- Deep Belief Networks深信度网络,主要应用于图像识别和语音处理领域
- Convolutional Neural Networks,CNNs是受早期的延时神经网络(TDNN)的影响。延时神经网络通过在时间维度上共享权值降低学习复杂度,适用于语音和时间序列信号的处理。
- 深度学习算法在计算上比普通机器学习算法更复杂,因而对时间和机器资源的要求更高,相应地,也取得了比普通机器学习算法更好的计算效果。
目前深度学习方法都用于处理图形,或者一些生物分子的结构还有序列上面,那么这个方法是否能够直接适用于表达谱这种数据呢,比如用表达谱作特征区分疾病和正常样本?我认为表达谱数据的特点是含有很大部分的噪音,不一定所有基因表达都与所研究的疾病相关。如果用这种给出的训练样本有噪音的情况,深度学习方法能不能自动学习而去除噪音的影响?
- 能直接应用于表达谱,但是深度学习对于有大量噪声的数据的效果不是很好。
- 用深度学习在生物学上的应用主要有两个难点,1)分析的数据集很难获取。2)计算量非常大,需要很好的硬件支持。
- D-GEX: 深度学习在表达谱上的应用的一个开源案例
- 其他参考
深度学习方法层数选择以及每一层所用的模型有什么技巧吗?
- 不同的算法,以及处理问题不同,不能一概而论。现在处于各自摸索阶段,在选择上没有什么理论的依据。
- 深度学习做股票预测靠谱吗?
- 所谓的深度学习不过是基于历史数据进行拟合的归纳法罢了,如果把深度学习用来做股票预测,长期的是expected亏钱的,因为市场在变,规律在变,历史可能重演,但是又不尽相同。
- Deep learning能做一切数据挖掘有关的事情,区别在于你能不能结合自身的经验去建立一个较优的模型,让learning更加的“高效”,这种“高效”包含但不限于:学习时间、学习误差率、学习鲁棒性、学习所耗费的资源等。
- Deep learning处理的数据前期至少要求是相对全面的,不全面的数据、甚至如果有重要的数据有所隐藏,对于任何学习模型来讲基本都是灾难的。
- Deep learning所谓的模型,对于目前而言,受限于基础理论,建立模型的过程是渐进的、甚至是需要人工的,所以“调参”的手段是有很大的“主观成分”在里面的。
- Deep learning是统计学和机器学习两门科学的交叉科学,它的宗旨是通过统计学习方法运用机器学习的运算(实现)思路,让机器帮我们去计算各种事件出现的概率,协助我们去分类大数据、预测新的样本为【某个特定分类】的概率等等。但是,仅仅是“概率”,既然是“概率”必然也就只是可能性而已。