假设检验
假设检验(Hypothesis Testing)是数理统计学中根据一定假设条件由样本推断总体的一种方法。它根据数据样本所提供的证据,指定是肯定还是否定有关总体的声明。具体作法是:根据问题的需要对所研究的总体作某种假设,记作H0;选取合适的统计量,这个统计量的选取要使得在假设H0成立时,其分布为已知;由实测的样本,计算出统计量的值,并根据预先给定的显著性水平进行检验,作出拒绝或接受假设H0的判断。(可使用 p 值来做出判断。如果 p 值小于显著性水平(用 α 或 alpha 表示),则可以否定原假设。)
常用的假设检验方法有u—检验法、t检验法、χ2检验法(卡方检验)、F—检验法,秩和检验等。
I. 置信区间
机器学习本质上是对条件概率或概率分布的估计,而这样的估计到底有多少是置信度?这里就涉及到统计学里面的置信区间与置信度。
很多答案当中用关于真值的概率描述来解释置信区间是不准确的。我们平常使用的频率学派(frequentist)95% 置信区间的意思并不是真值在这个区间内的概率是 95%。由于在频率学派当中,真值是一个常数,而非随机变量(后者是贝叶斯学派) ,所以我们不对真值做概率描述。
只有贝叶斯学派才会说某个特定的区间包含真值的概率是多少,但这需要我们为真值假设一个先验概率分布(prior distribution)。这不适用于我们平常使用的基于频率学派的置信区间构造方法。
换言之,我们可以说,如果我们重复取样,每次取样后都用这个方法构造置信区间,有 95% 的置信区间会包含真值。然而(在频率学派当中)我们无法讨论其中某一个置信区间包含真值的概率。
换种方法说,假设我们还没有取样,但已经制定好取样后构造 95% 置信区间的方法。我们可以说取样一次以后,获得的那个置信区间(现在还不知道)包含真值的概率是 95%。然而在取样并得到具体的一个区间之后,在频率学派框架下就无法讨论这个区间包含真值的概率了1。
- 置信区间,提供了一种区间估计的方法。
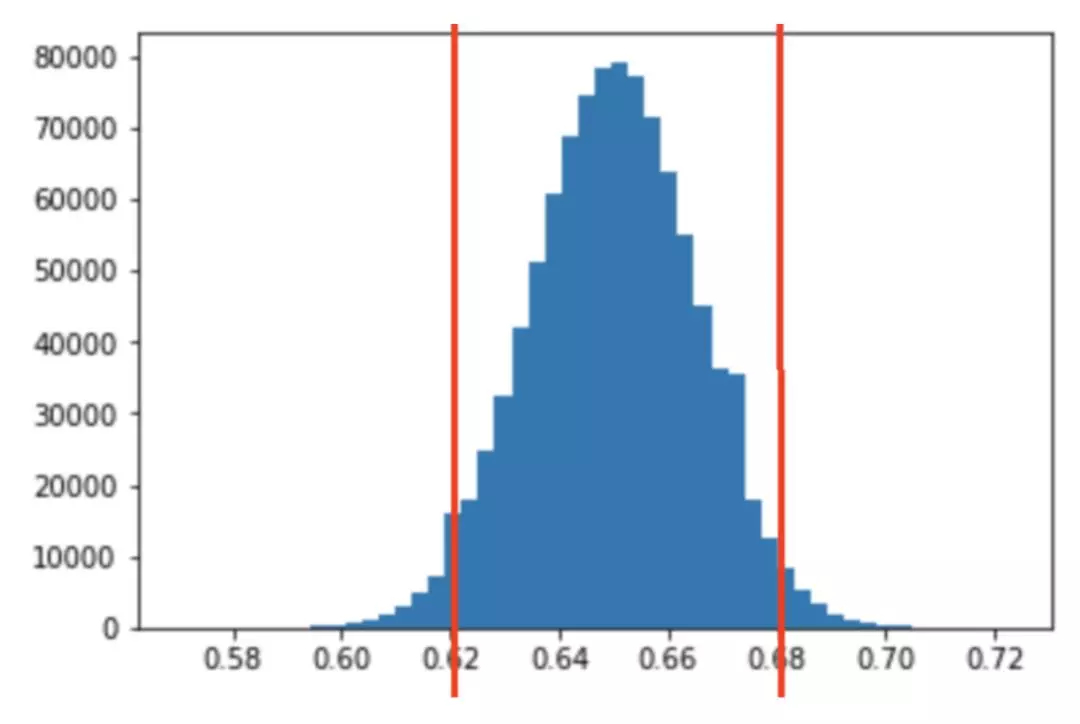
假设你想知道美国有多少人热爱足球2。为了得到 100% 正确的答案,你可以做的唯一一件事是向美国的每一位公民询问他们是否热爱足球。根据维基百科,美国有超过 3.25 亿的人口。与 3.25 亿人谈话并不现实,因此我们必须通过问更少的人来得到答案。我们可以通过在美国随机抽取一些人(与更少人交谈)并获得热爱足球的人的百分比来做到这一点,但是我们不能 100% 确信这个数字是正确的,或者这个数字离真正的答案有多远。所以,我们试图实现的是获得一个区间,例如,对这个问题的一个可能的答案是:「我 95% 相信在美国足球爱好者的比例是 58% 至 62%」。这就是置信区间名字的来源,我们有一个区间,并且我们对它此一定的信心。因此,假设我们随机抽取了 1000 个美国人的样本,我们发现,在 1000 人中有 63% 的人喜欢足球,我们能假设(推断)出整个美国人口的情况吗?让我们回到我们的例子,我们抽取了 1000 人的样本,得到了 63%,我们想知道,随机抽样的 1000 人中有 63% 的足球爱好者的概率是多少。使用这个直方图,我们可以说有(大概)25%的概率,我们会得到一个小于或等于 63% 的值。该理论告诉我们,我们实际上并不需要得到无限的样本,如果我们随机选择 1000 人,只有 63% 的人喜欢足球是可能发生的。所以,我们不知道在美国热爱足球的人的实际比例。我们所知道的是,如果我们从总体分布取无数个样本,它将如下所示:
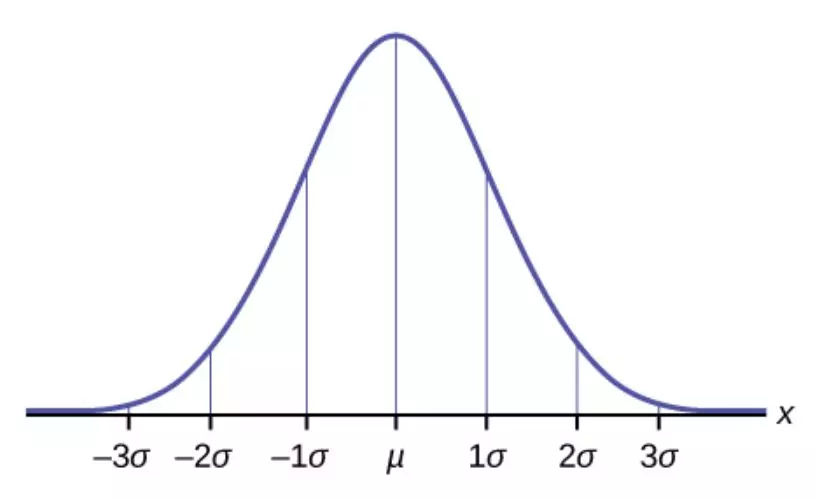
这里 μ 是总体分布的平均值(我们例子中足球爱好者的实际百分比),σ 是总体分布的标准差。如果我们知道这一点(并且我们知道标准差),我们可以说约 64% 的样本会落在红色区域,或者 95% 以上的样品会落在图中的绿色区域之外:
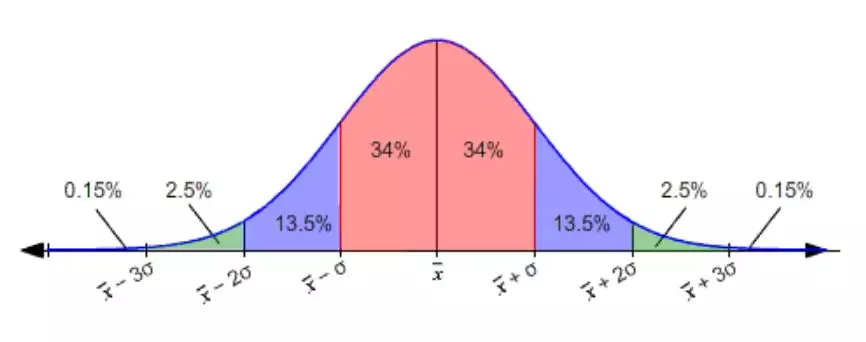
如果我们在之前假设的实际百分比 65% 上使用该图,那么 95% 以上的样本将在 62% 和 68% 之间(+ - 3)。当然,距离是对称的,所以如果样本有 95% 落在在实际百分比 -3 和 +3 之间,那么真实百分比落在样本百分比 -3 和 +3 之间的概率为 95%。如果我们抽取一个样本,得到了 63%,那么我们可以说我们 95% 确信实际比例在 60%(63-3)和 66%(63 + 3)之间。这就是置信区间,区间为 63 + -3,置信度为 95%。
II. 假设检验分类
假设检验可以分为参数检验和非参数检验。在用样本数据对总体信息做出统计推断时,通常要求抽样应满足随机性和独立性,因为几乎所有的抽样定理都是建立在数据独立的基础之上的。而在用样本数据对正态总体参数做出统计推断(例如参数估计和假设检验)时,还要附加一个要求:样本数据应服从正态分布,这种数据分布类型已知的总体参数的假设称为参数假设检验。与参数假设检验相对应的还有非参数假设检验,例如分布的正态性检验,样本的随机性检验等,这类检验通常只假定分布是连续的或对称的,并不要求数据服从正态分布。
II.I. 参数检验
参数检验要求样本来源于正态总体(服从正态分布),且这些正态总体拥有相同的方差,在这样的基本假定(正态性假定和方差齐性假定)下检验各总体均值是否相等,属于参数检验。
参数检验的四种函数分为anova1,anova2,anovan,manova1。他们都基于共同的两个假设:正态性假定和方差齐性假定 ,分别对应着函数lillietest 和vartestn。
- 设总体服从正态分布,在方差已知的条件下,若对期望进行检验,可用U-检验。
- 设总体服从正态分布,如果方差未知,对期望进行检验,可用T—检验。
- 对于单个正态总体有关方差检验的问题,我们可用\(\chi^2\)—检验来解决。
- 比较两个正态总体的方差是否相等,我们就要用下面的F—检验。
II.I.I. T检验和F检验的关系
t检验有单样本t检验,配对t检验和两样本t检验。单样本t检验:是用样本均数代表的未知总体均数和已知总体均数进行比较,来观察此组样本与总体的差异性。配对t检验:是采用配对设计方法观察以下几种情形,1,两个同质受试对象分别接受两种不同的处理;2,同一受试对象接受两种不同的处理;3,同一受试对象处理前后。
F检验又叫方差齐性检验。
若是单组设计,必须给出一个标准值或总体均值,同时,提供一组定量的观测结果,应用t检验的前提条件就是该组资料必须服从正态分布;若是配对设计,每对数据的差值必须服从正态分布;若是成组设计,个体之间相互独立,两组资料均取自正态分布的总体,并满足方差齐性。之所以需要这些前提条件,是因为必须在这样的前提下所计算出的t统计量才服从t分布,而t检验正是以t分布作为其理论依据的检验方法。简单来说就是实用T检验是有条件的,其中之一就是要符合方差齐次性,这点需要F检验来验证。
t检验过程,是对两样本均数(mean)差别的显著性进行检验。在两样本t检验、惟t检验中须知道两个总体的方差(Variances)是否相等;t检验值的计算会因方差是否相等而有所不同。也就是说,t检验须视乎方差齐性(Equality of Variances)结果。所以,SPSS在进行t-test for Equality of Means的同时,也要做Levene's Test for Equality of Variances ,故所以就用F检验(F值)。(从两研究总体中随机抽取样本,要对这两个样本进行比较的时候,首先要判断两总体方差是否相同,即方差齐性。若两总体方差相等,则直接用t检验,若不等,可采用t'检验或变量变换或秩和检验等方法。)
到底看哪个Levene's Test for Equality of Variances一栏中sig,还是看t-test for Equality of Means中那个Sig. (2-tailed)啊? 答案是:两个都要看。先看Levene's Test for Equality of Variances,如果方差齐性检验「没有显著差异」,即两方差齐(Equal Variances),故接著的t检验的结果表中要看第一排的数据,亦即方差齐的情况下的t检验的结果。 反之,如果方差齐性检验「有显著差异」,即两方差不齐(Unequal Variances),故接著的t检验的结果表中要看第二排的数据,亦即方差不齐的情况下的t检验的结果。
II.I.II. 单正态总体均值的假设检验
方差未知,单个正态总体的均值μ的假设检验( t检验法) 1
2
3
4
5
6
7
8
9
10
11
12函数
ttest
格式
h = ttest(x,m) % x为正态总体的样本,m为均值μ0,显著性水平为0.05
h = ttest(x,m,alpha) %alpha为给定显著性水平
[h,sig,ci] = ttest(x,m,alpha,tail) %sig为观察值的概率,当sig为小概率时则对原假设提出质疑,ci为真正均值μ的1-alpha置信区间。
说明 若h=0,表示在显著性水平alpha下,不能拒绝原假设;
若h=1,表示在显著性水平alpha下,可以拒绝原假设。
原假设: ,
若 tail=0,表示备择假设: (默认,双边检验);
tail=1,表示备择假设: (单边检验);
tail=-1,表示备择假设: (单边检验)。
II.I.III. 单正态总体方差的假设检验
II.I.IV. 两正态总体均值的假设检验
两个正态总体均值差的检验(t检验) 1
2
3
4
5
6
7
8
9
10
11两个正态总体方差未知但等方差时,比较两正态总体样本均值的假设检验
函数 ttest2
格式 [h,sig,ci]=ttest2(X,Y) %X,Y为两个正态总体的样本,显著性水平为0.05
[h,sig,ci]=ttest2(X,Y,alpha) %alpha为显著性水平
[h,sig,ci]=ttest2(X,Y,alpha,tail) %sig为当原假设为真时得到观察值的概率,当sig为小概率时则对原假设提出质疑,ci为真正均值μ的1-alpha置信区间。
说明 若h=0,表示在显著性水平alpha下,不能拒绝原假设;
若h=1,表示在显著性水平alpha下,可以拒绝原假设。
原假设: , ( 为X为期望值, 为Y的期望值)
若 tail=0,表示备择假设: (默认,双边检验);
tail=1,表示备择假设: (单边检验);
tail=-1,表示备择假设: (单边检验)。
II.I.V. 两正态总体方差的假设检验
II.I.VI. 大样本非正态总体均值的假设检验
II.II. 非参数检验
当数据不满足正态性和方差齐性假定时,参数检验可能会给出错误的答案,此时应采用基于秩的非参数检验。
大样本情形下,对于非正态总体,可以利用中心极限定理近似用标准正态分布进行假设检验。小样本情形,若总体不是正态分布的,可以使用非参数检验的方法。非参数检验的效率稍差,但适应各种总体类型,应用范围较广。
两种非参数检验:Kruskal-Wallis检验,Friedman检验。
II.II.I. 游程检验
在实际应用中,需要对样本数据的随机性和独立性作出检验,这要用到游程检验,它是一种非参数检验,用来检验样本数据的随机性,通常人们认为满足随机性的样本数据也满足独立性。在以一定顺序(如时间)排列的有序数列中,具有相同属性(如符号)的连续部分被称为一个游程,一个游程中所包含数据的个数称为游程的长度,通常用R表示一个数列中的游程总数。
MATLAB统计工具箱中提供了runstest函数,用来做游程检验。
II.II.II. friedman test
friedman test中的p值是该test中使用的Chi-sq分布的q值,当该值小于我们设定的significance level时,我们认为假设(treatment没有影响)成立时极小概率的事件发生,从而拒绝该假设。在matlab中的treatment设定为矩阵的列,即列对应的变量对数据没有影响。
stats结构体中的meanranks是各列rank的平均值,在matlab中是给同一行中较大的值赋给较大的ra搜索nk,所以最小的值的rank为1,第二小的为2,以此类推。每行赋给rank后就求每列的平均rank,如果列变量对数据影响不大的话rank 一般会比较接近,friedman test用这些平均值构建了一个统计量,它符合chi-sq分布,如果该分布下极小概率的事件发生,我们拒绝假设并认为列变量对数据有影响。
II.II.III. 符号检验
符号检验还可用于配对样本的比较检验,符号检验法是通过两个相关样本的每对数据之差的符号进行检验,从而比较两个样本的显著性。具体地讲,若两个样本差异不显著,正差值与负差值的个数应大致各占一半。
MATLAB统计工具箱中提供了signtest函数,用来符号检验。
两个总体中位数相等的假设检验——符号检验
1 | 函数 |
II.II.IV. 曼-惠特尼秩和检验
曼-惠特尼U检验又称“曼-惠特尼秩和检验”,是由H.B.Mann和D.R.Whitney于1947年提出的。它假设两个样本分别来自除了总体均值以外完全相同的两个总体,目的是检验这两个总体的均值是否有显著的差别。
MATLAB统计工具箱中提供了ranksum函数,用来做秩和检验。
两个总体一致性的检验——秩和检验 1
2
3
4
5
6
7
8函数 ranksum
格式 p = ranksum(x,y,alpha) %x、y为两个总体的样本,可以不等长,alpha为显著性水平,它必须为0和1之间的数量。该检验零假设认为x和y的总体是同分布的。
[p,h] = ranksum(x,y,alpha) % h为检验结果,h=0表示X与Y的总体差别不显著,h=1表示X与Y的总体差别显著
[p,h,stats] = ranksum(x,y,alpha) %stats中包括:ranksum为秩和统计量的值以及zval为过去计算p的正态统计量的值
说明:
p返回产生两独立样本的总体是否相同的显著性概率,h返回假设检验的结果。
如果x和y的总体差别不显著,则h为零;如果x和y的总体差别显著,则h为1。
如果p接近于零,则不一致较明显,可对原假设质疑。
II.II.V. Wilcoxon符号秩检验
符号检验只考虑的分布在中位数两侧的样本数据的个数,并没有考虑中位数两侧数据分布的疏密程度,这就使得符号检验的结果比较粗糙,检验功率较低。统计学家维尔科克森在1945年,提出了一种更为精细的“符号秩检验法”,该方法是在配对样本的符号检验基础上发展起来的,比传统的单独用正负号的检验更加有效。它适用于单个样本中位数的检验,也适用于配对样本的比较检验,但并不要求样本之差服从正态分布,只要求对称分布即可。
威尔科克森符号秩检验(Wilcoxon Signed Rank Test)亦称威尔科克伦代符号的等级检验,是由威尔科克森(F·Wilcoxon)于1945年提出的。该方法是在成对观测数据的符号检验基础上发展起来的,比传统的单独用正负号的检验更加有效。
在Wilcoxon符号秩检验中,它把观测值和零假设的中心位置之差的绝对值的秩分别按照不同的符号相加作为其检验统计量。它适用于T检验中的成对比较,但并不要求成对数据之差di服从正态分布,只要求对称分布即可。检验成对观测数据之差是否来自均值为0的总体(产生数据的总体是否具有相同的均值)。
paired t-test:检验两组均值是否相等。 Wilcoxon signed-rank test: 检验两组的中位数是不是相等。这个是paired t-test的非参检验版本的类比。从名字可以看出就是用两组数的rank信息。因为t test是在正态条件下,当数据偏的离谱的时候,就没法用t了。所以只好做出牺牲,用Wilcoxon signed-rank test。 但于此同时,你可以看到,你能得到的结果弱的多了。
在小样本下,可能不符合normal分布,同样,用渐近分布(样本量趋向无穷),也不合适(应为只有5个样本),不满足T检验要求,那么采用非参(放宽了这个条件)。
wilcoxon signed rank test针对一元数据 or 配对数据的。wilcoxon rank sum test or MWW Test是两组数据的。
MATLAB统计工具箱中提供了signrank函数,用来做Wilcoxon(威尔科克森)符号秩检验。
两个总体中位数相等的假设检验——符号秩检验 1
2
3
4函数 signrank
格式 p = signrank(X,Y,alpha) % X、Y为两个总体的样本,长度必须相同,alpha为显著性水平,P两个样本X和Y的中位数相等的概率,p接近于0则可对原假设质疑。
[p,h] = signrank(X,Y,alpha) % h为检验结果:h=0表示X与Y的中位数之差不显著,h=1表示X与Y的中位数之差显著。
[p,h,stats] = signrank(x,y,alpha) % stats中包括:signrank为符号秩统计量的值以及zval为过去计算p的正态统计量的值。
III. 显著性检验
无论你从事何种领域的科学研究还是统计调查,显著性检验作为判断两个乃至多个数据集之间(实验组与对照组之间)是否存在差异以及差异是否显著的方法被广泛应用于各个科研领域。
在统计学中,显著性检验是“统计假设检验”的一种,所谓统计假设检验就是事先对总体(随机变量)的参数或总体分布形式做出一个假设,然后利用样本信息来判断这个假设是否合理。而把只限定第一类错误概率的统计假设检验就称之为显著性检验。
任何人在使用显著性检验之前必须在心里明白自己的科研假设是什么,否则显著性检验就是“水中月,镜中花”,可望而不可即。如果原假设为真,而检验的结论却劝你放弃原假设。此时,我们把这种错误称之为第一类错误。通常把第一类错误出现的概率记为α。如果原假设不真,而检验的结论却劝你不放弃原假设。此时,我们把这种错误称之为第二类错误。通常把第二类错误出现的概率记为β。通常只限定犯第一类错误的最大概率α,不考虑犯第二类错误的概率β。我们把这样的假设检验称为显著性检验,概率α称为显著性水平。
eg 赵先生开了一家日用百货公司,该公司分别在郑州和杭州开设了分公司。现在存在下列数据作为两个分公司的销售额,集合中的每一个数代表着一年中某一个月的公司销售额。现在,赵先生想要知道两个公司的销售额是否有存在明显的差异。 郑州分公司Z = {23,25,26,27,23,24,22,23,25,29,30} 杭州分公司H = {24,25,23,26,27,25,25,28,30,31,29}
他的假设就是“样本集Z(郑州分公司)和样本集H(杭州分公司)不存在显著性差异,换言之这两个集合没有任何区别(销售额间没有区别)!”这个假设(Hypothesis)正是方差检验的原假设(null hypothesis)。
在显著性水平α =0.05的情况下,p>0.05接受原假设,p值<0.05拒绝原假设。
方差检验不适用于估计参数和估计总体分布,而是用于检验试验的两个组间是否有差异。而方差检验正是用于检测我们所关心的是这两个集合(两个分布)的均值是否存在差异。
虽然杭州分公司的年平均销售额26.63大于郑州分公司的销售额25.18。方差检验的p 值= 0.2027,意味着销售额没有明显差异。
IV. 讨论
IV.I. 所有的检验统计都是正态分布的吗
并不完全如此,但大多数检验都直接或间接与之有关,可以从正态分布中推导出来,如t检验、f检验或卡方检验。这些检验一般都要求:所分析变量在总体中呈正态分布,即满足所谓的正态假设。许多观察变量的确是呈正态分布的,这也是正态分布是现实世界的基本特征的原因。当人们用在正态分布基础上建立的检验分析非正态分布变量的数据时问题就产生了,(参阅非参数和方差分析的正态性检验)。这种条件下有两种方法:一是用替代的非参数检验(即无分布性检验),但这种方法不方便,因为从它所提供的结论形式看,这种方法统计效率低下、不灵活。另一种方法是:当确定样本量足够大的情况下,通常还是可以使用基于正态分布前提下的检验。后一种方法是基于一个相当重要的原则产生的,该原则对正态方程基础上的总体检验有极其重要的作用。即,随着样本量的增加,样本分布形状趋于正态,即使所研究的变量分布并不呈正态。
IV.II. 如何判定结果具有真实的显著性
在最后结论中判断什么样的显著性水平具有统计学意义,不可避免地带有武断性。换句话说,认为结果无效而被拒绝接受的水平的选择具有武断性。实践中,最后的决定通常依赖于数据集比较和分析过程中结果是先验性还是仅仅为均数之间的两两>比较,依赖于总体数据集里结论一致的支持性证据的数量,依赖于以往该研究领域的惯例。通常,许多的科学领域中产生p值的结果≤0.05被认为是统计学意义的边界线,但是这显著性水平还包含了相当高的犯错可能性。结果0.05≥p>0.01被认为是具有统计学意义,而0.01≥p≥0.001被认为具有高度统计学意义。但要注意这种分类仅仅是研究基础上非正规的判断常规。
IV.III. p值统计学意义
In statistical hypothesis testing, the p-value or probability value is the probability for a given statistical model that, when the null hypothesis is true, the statistical summary (such as the sample mean difference between two compared groups) would be the same as or of greater magnitude than the actual observed results.[1] The use of p-values in statistical hypothesis testing is common in many fields of research[2] such as economics, finance, political science, psychology,[3] biology, criminal justice, criminology, and sociology.[4] Their misuse has been a matter of considerable controversy.
结果的统计学意义是结果真实程度(能够代表总体)的一种估计方法。专业上,p值为结果可信程度的一个递减指标,p值越大,我们越不能认为样本中变量的关联是总体中各变量关联的可靠指标。p值是将观察结果认为有效即具有总体代表性的犯错概率。
这里有一个超级好懂的解释:
- P值大小指示的是假阳性的出现概率,代表了研究者对假阳性的容忍度。“P≤0.05 reflects our level of tolerance for false-positive results."
- 当我们检验一个统计假设H0时,p值是当H0为真时样本结果或者更极端结果出现的概率。p值越小,也就越应该拒绝原假设,也就是结果越显著。
从本质上讲,p值只是结果在现有实验条件下是否可能是随机产生的度量,它对应的因果链是p值越小,结果越不可能随机产生,贝叶斯因子也就越大。但这不代表Pr(H1|xobs)/Pr(H0|xobs)就越大。因为根据上述的公式,它还依赖于H1和H0概率的比值,也就是先验风险。
如p=0.05提示样本中变量关联有5%的可能是由于偶然性造成的。即假设总体中任意变量间均无关联,我们重复类似实验,会发现约20个实验中有一个实验,我们所研究的变量关联将等于或强于我们的实验结果。(这并不是说如果变量间存在关联,我们可得到5%或95%次数的相同结果,当总体中的变量存在关联,重复研究和发现关联的可能性与设计的统计学效力有关。)在许多研究领域,0.05的p值通常被认为是可接受错误的边界水平。
2014年2月,美国曼荷莲学院(Mount Holyoke College)数学与统计学教授George Cobb在美国统计学会(American Statistical Association, ASA)的论坛上提出了两个问题:问:为什么这么多学校都在教“P=0.05”?答:因为科学界和期刊编辑现在还用这个。问:为什么这么多人还在用“P=0.05”?答:因为学校就是这么教的。
为什么选择.005呢? 作者们写下如下两点原因:第一、.005大约与贝叶斯因子的14~26相对应,是比较强的证据;第二、.005在许多研究领域者能够较好地控制假阳性(关于假阳性的控制,可以看这个帖子:控制一类错误和二类错误);
There is widespread agreement that p-values are often misused and misinterpreted.[21][22][23] One practice that has been particularly criticized is accepting the alternative hypothesis for any p-value nominally less than .05 without other supporting evidence. Although p-values are helpful in assessing how incompatible the data are with a specified statistical model, contextual factors must also be considered, such as "the design of a study, the quality of the measurements, the external evidence for the phenomenon under study, and the validity of assumptions that underlie the data analysis".[23] Another concern is that the p-value is often misunderstood as being the probability that the null hypothesis is true.[23][24] Some statisticians have proposed replacing p-values with alternative measures of evidence,[23] such as confidence intervals,[25][26] likelihood ratios,[27][28] or Bayes factors,[29][30][31] but there is heated debate on the feasibility of these alternatives.[32][33] Others have suggested to remove fixed significance thresholds and to interpret p-values as graded measures of the strength of evidence against the null hypothesis.[34]
在阅读了太多不可重复或者包含统计错误的论文(或者同时出现)后,ASA决定行动起来:2016年3月7日,ASA正式发表了使用和解释P值的“六原则”(Wasserstein, R. L., & Lazar, N. A. (2016). The ASA's statement on p-values: context, process, and purpose. The American Statistician)。我们使用P值来检测组间或方法间的差别、评估目标变量间的关系,等等。但ASA指出,P值被广泛误用了。
ASA对这六个原则进行了具体的阐释:
1. P值可以指示数据与一个给定模型的不相容程度。(P-values can indicate how incompatible the data are with a specified statistical model.)
我们基于一系列的假设建立的模型称为原假设;我们同时还会建立零假设(null hypothsis),即指某种我们想要检测的效应不存在,例如两组无差,或者某个因子与结果无关。P值越小,说明数据与零假设之间越不相容。这里的不相容,可以解释为对零假设的存疑程度。
2. P值不能衡量某假设为真的概率,也不能衡量数据仅由随机因素造成的概率。(P-values do not measure the probability that the studied hypothesis is true, or the probability that the data were produced by random chance alone.)
尽管研究者常常希望计算出零假设是否为真,或是算出观测结果仅由随机事件造成的概率,但P值的作用并不是这个,P值只解释数据与假设之间的关系,它并不解释假设本身。
3. 科学结论、商业决策或政策制定,不应只取决于P值是否达到了一个给定标准。(Scientific conclusions and business or policy decisions should not be based only on whether a p-value passes a specific threshold. )
为了给某种科学主张或论断提供佐证而把数据分析或科学评估[我怀疑“还原”这个词是不是有点不准确,但我可以理解,“简化”?]简化成一种机械性的规则(例如p<0.05),这会导致错误的结论和糟糕的决定。一个结论的正确与否并不会因为研究者算出的P值大于还是小于0.05而改变[虽然原作很绕,但这句话吐槽还是很清楚的,它吐槽的是一种是否通过了类似0.05之类的二元类的方法:后文他的观点是如果用P值的话,应该给出具体的大小。如果你改成“P值大小”,实际上把槽点扭曲了。]。研究者需要将很多因子纳入考虑来作出科学推断,包括研究设计、测量的质量、与研究对象有关的外部证据,以及分析数据时使用的假设的合理性等。决策者常常需要根据研究结果作出“做”或“不做”的决定,但p值本身不能决定决策的正确与否。科研界将显著性标准(例如p<0.05)作为发表科学发现(暗示了其真实性)的“许可证”广泛使用,然而这却扭曲了科研的过程。
4. 研究者需对研究进行完整的报告、保证透明度,才能做出合理的推论。(Proper inference requires full reporting and transparency. )
研究者不应选择地报道P值和相关的统计分析。某项研究可能使用了好几种分析方法,而研究者只报告其中的一部分(特别是那些符合标准的),这就使得P 值难以解释。一旦研究者根据统计结果选择性地展示相应的方法,而读者对此并不知情,结果的有效性就打了折扣。研究者应该展示研究过程中检验过的假设的数量、数据收集的方法、所有使用过的统计方法和相应的P值。
5. P值或统计显著性并不能衡量效应的大小和结果的重要性。(A p-value, or statistical significance, does not measure the size of an effect or the importance of a result. )
某项个结果的统计显著性并不代表其在科学、人文的或者经济上的重要性。P值小并不意味着效应更重要,P值大也不代表不重要或没有效应。无论某个效应的影响有多小,当样本量足够大或测量精度足够高时,总能得到小的P值。对于相同的效应,当测量精度不同时,得到不同的P值也会不同。
6. P值本身并不能衡量模型或假设的可信度。(By itself, a p-value does not provide a good measure of evidence regarding a model or hypothesis.)
研究者应该意识到,在没有一定的背景时,P值能提供的信息非常有限。接近0.05的P值只能为反驳零假设提供非常弱的证据。同样的,相对大的P值也不一定意味着证据就偏向支持零假设,还是有很多其他的假设可能导致现有的结果。因此,当其他方法适用时,研究者对数据的分析不应止于P值分析。
为进一步解读“六原则”的意义,关注论文撤稿的博客retractionwatch.com采访了ASA执行主任Ron Wasserstein。
R:为什么现在发表“六原则”?是否是因为科学发展到现在阶段让P值误用成为了一个特别急迫的问题?
W:我们是被现在持续加剧的可重复性危机以及人们将此归咎于统计方法的现象刺激了。学术期刊《基础和应用社会心理学》(Basic and Applied Social Psychology)的编辑对于P值的误用和误解感到如此的无力,因此在2015年决定禁用这一指标。这一做法更证实了对P值的信任危机已经到来,ASA不能再坐视不管。
R:部分原则看起来非常直白,但我对第二条有点疑问。我常常听说P值可用来估计数据是否仅由随机过程产生,为什么这是一种错误的想法?
W:让我们设想一个简单的情境来解释这样的想法意味着什么。假设出现了一种针对某严重疾病的新疗法,研究者宣称这比已有的疗法更有效。我们选取2个情况类似的病人配对,一共得到5对这样的病人,给每对中的两个病人随机分配新、旧两种疗法。零假设(无效假设)是指新旧两种疗法在5组内都有50:50的概率更有效。假如零假设为真,新疗法在5个组中都表现出更好的概率是(1/2)5=1/32,约等于0.03.如果在实验中,每组接受新疗法的病人都表现的更好,我们就会得到0.03的p值。它代表的是这样一种概率:当新旧两种疗法实际效果相同时,实验结果显示新疗法全比旧疗法好的概率(即假阳性的概率,译者注)。[如果加注的话这里就很合适]但这不是新旧两种疗法效果相同的概率。
这可能很微妙,但绝非诡辩。这是一个非常常见的逻辑谬误:为了让结论为真,你不得先不假定其为真,然后才能得到这个结论。如果你掉进了这个逻辑谬误,你得到的结论会变为“只有3%的概率这两种疗法疗效相当”,然后认为新疗法有97%的概率更好。你就犯了一个经典并且非常严重的错误。
R:在研究者使用和解释P值时,他们犯的最大的错误是什么?
W: 有几种错误特别普遍,并且导致了很大的问题。刚刚提到的那个就很常见。另一个是常见的误解是:计算出了较大的P值,就认为零假设为真。还有其他的误解,但引起我们更大重视的是误用的问题,特别是研究者把统计显著性作为科学价值的评价标准。这种误用是糟糕的决策和不能重复的研究的始作俑者之一,最终不仅会危害科学的进步,还会摧毁公众对科学的信任。
R:有没有哪些领域比其他领域出的错更多?
W: 据我所知还没有人研究过这个问题。我感觉所有科学领域都有诸多明显的错误,但也有研究非常漂亮地使用了统计学方法。但总体来说,在那些对被试者或试验单位进行了多重测量的研究中,P值更易被误用。这种测量方法会给予研究者成为“P值黑客”(即找到一种方法获得满意的P值)的机会,但这种机会却不能给科学本身带来任何益处。
R:你能否详细解释一下第四条——“研究者需对研究进行完整的报告、保证透明度,才能做出合理的推论”?
W: 这当然有很多可说的,但简而言之,从统计学的角度,这意味着要追踪和报道关于你对数据作的所有决定,包括数据收集的设计和执行过程,以及你在分析数据过程中做的一切。你是否以某种方式进行了跨组平均或合并了组间数据?你是否用数据来决定检测或控制哪个变量,或者在最终的分析中包括和删除了某个变量?你是否不断地增减变量,好让自己的回归模型和系数通过了某个显著性标准?这些决定,以及所有基于数据本身的决定都需要被包括在内。
R:在随ASA的声明一起发表的内容里,你提到希望学术界能够进入“后p<0.05”时代。这指的是什么呢?如果不使用P值的话,我们应该用什么代替它?
W:在后p<0.05时代,科学论证不应基于P值是否足够小。效应量和置信区间都应被郑重对待。统计结果应被理解为连续、而非二元的。当用这种方法考虑问题时,面对P值,我们应该看到一个数字,而不是一个不等式,如p=0.0168而非p<0.05。所有与推断有关的假设都应该被检测,包括和数据选择和分析方法有关的决定。在后p<0.05时代,数据分析仍然很重要,但没有一种数值,而且必然不是P值,能够代替统计思考和科学推理。
R: 还有什么要补充的么?
W:我们很快就会知道这份声明是否能达到它的目的。如果是的话,期刊将不再把统计显著性作为是否接受论文的标准。取而代之、被接受的论文的特征应是:试验设计、执行和分析被清晰细致地描述出来;结论建立在有效的统计解释和科学论点之上;报告得足够全面、透明,能够被其他人严格的审查。我认为这是杂志编辑想要做的,有人已经在做了,但也有一些人这被看起来简单的统计显著性所诱惑。
IV.III.I. p值的选取
Science杂志网站发布了Kelly Servick 撰写的评论:It will be much harder to call new findings ‘significant’ if this team gets its way. Kelly Servick依据和引用了Daniel J. Benjamin等72位作者联合署名的、发表在PsyArXiv预发布平台上的文章:Redefine Statistical Significance. Redefine Statistical Significance即将正式发表在Nature Human Behavior杂志上。P < 0.05的使用及其结果解释,一直受到人们的诟病。为此,Daniel J. Benjamin等建议摒弃一直以来使用的P < 0.05阈值,作为有“统计学意义”的评价金标准;改用更为严格的P < 0.005阈值来作为有“统计学意义”的评价金标准。Daniel J. Benjamin等认为:使用P < 0.005代替P < 0.05,可以将假阳性率从33%(P < 0.05)降到 5%(P < 0.005)。当P < 0.005时,可以认为具有“统计学意义”;当0.005< P <0.05时,可以认为具有“suggestive或暗示”价值。依据Daniel J. Benjamin等作者的估计,选择P < 0.005阈值时,实验研究的样本量至少要增加70%。Daniel J. Benjamin解释道:大多数研究人员都认识到,在P < 0.05阈值条件下获得的证据,其可靠性差。他们的文章以及提出的新标准是为了帮助人们更好的理解实验研究证据。如果,Daniel J. Benjamin等72位作者的观点能够获得科学界的认可和支持,是否就会意味着使用了百年以上的P < 0.05阈值将退出历史舞台?!我们将拭目以待。