机器学习
机器学习(Machine Learning,常简称为ML)研究的是计算机怎样模拟人类的学习行为,以获取新的知识或技能,并重新组织已有的知识结构使之不断改善自身。简单一点说,就是计算机从数据中学习出规律和模式,以应用在新数据上做预测的任务。机器学习在近30多年已发展为一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、计算复杂性理论等多门学科。
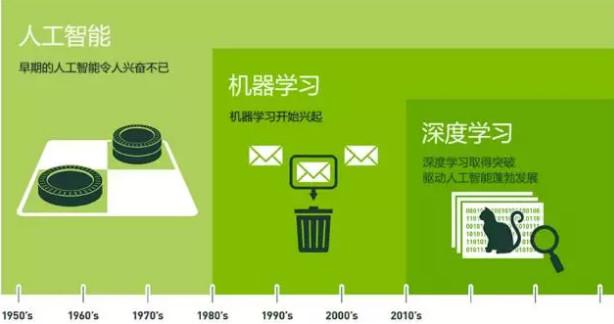
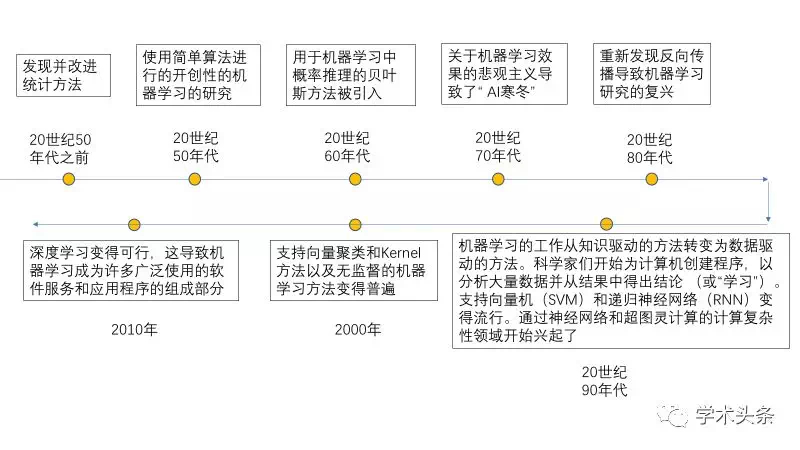
- 它是人工智能(Artificial Intelligence,常简称为AI)的一个重要子领域,而人工智能又与更广泛的数据挖掘(Data Mining,常简称为DM)和知识发现(Knowledge Discovery in Database,常简称为KDD)领域相交叉。
- 机器学习是人工智能的一个分支。人工智能的研究是从以“推理”为重点到以“知识”为重点,再到以“学习”为重点,一条自然、清晰的脉络。
- 机器学习是实现人工智能的一个途径,即以机器学习为手段解决人工智能中的问题。
- 机器学习是人工智能的核心,应用遍及人工智能的各个领域,
机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。为此,机器学习主要关注于模式识别。机器学习有助于识别数据集内的模式,并因此尝试根据现有数据进行预测。深度学习是一种实现机器学习的技术1。
一个简单的数学建模,我们需要考虑的是:1. 要做什么?2. 怎么做?3. 这样做合理吗?4. 如果这样做,假设那些可以改变?5. 这样做需要用到那些模型?6. 这种模型简洁吗?7. 确定了这种模型,怎么求解?8. 求解出来了,与现实合理吗?9. 在这个模型中,存在什么缺点,怎么去优化?10. 总结。
I. 发展过程
目前机器学习已经在数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、DNA序列测序、战略游戏和机器人等多个方面都得到了运用。
II. 实现过程
华盛顿大学 eScience Institute 和 Institute for Neuroengineering 的数据科学博士后 Michael Beyeler2介绍了如何依靠已有的方法(模型选择和超参数调节)去指导你更好地去选择算法。
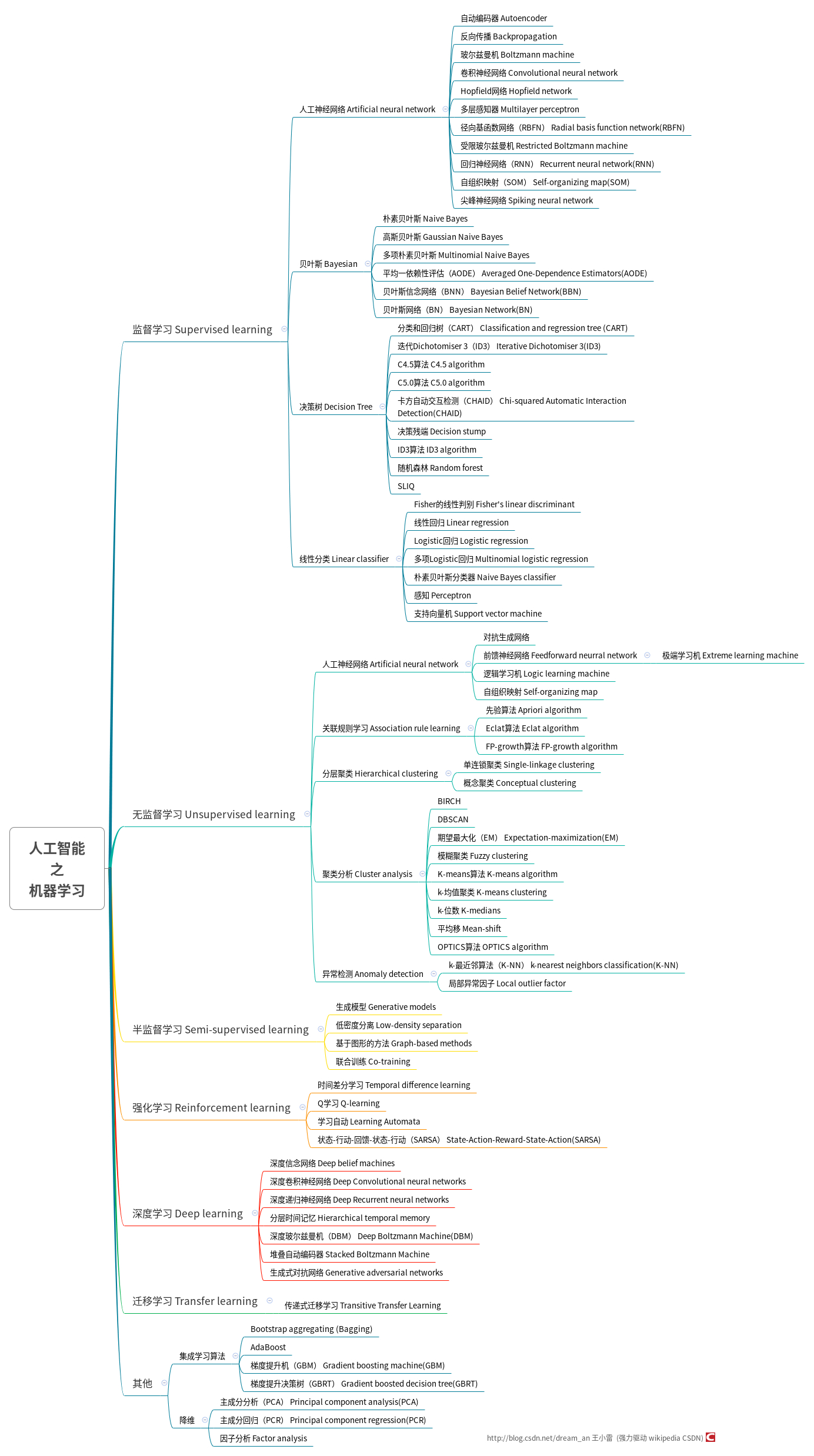
- 了解基本知识。机器学习里面三个主要类别:监督学习,无监督学习和强化学习。
- 在监督学习(supervised learning)中,每个数据点都会获得标注,如类别标签或与数值相关的标签。一个类别标签的例子:将图片分类为「猫」或「狗」;数值标签的例子如:预测一辆二手车的售价。监督学习的目的是通过学习许多有标签的样本,然后对新的数据做出预测。例如,准确识别新照片上的动物(分类)或者预测二手车的售价(回归)。
- 在无监督性学习(unsupervised learning)中,数据点没有相关的标签。相反,无监督学习算法的目标是以某种方式组织数据,然后找出数据中存在的内在结构。这包括将数据进行聚类,或者找到更简单的方式处理复杂数据,使复杂数据看起来更简单。
- 在强化学习(reinforcement learning)中,算法会针对每个数据点来做出决策(下一步该做什么)。这种技术在机器人学中很常用。传感器一次从外界读取一个数据点,算法必须决定机器人下一步该做什么。强化学习也适合用于物联网应用。在这里,学习算法将收到奖励信号,表明所做决定的好坏,为了获得最高的奖励,算法必须修改相应的策略。
- 对问题进行分类
- 根据输入数据分类:如果我们的数据有标签,这就是一个监督学习问题;如果数据没有标签而且我们想找出数据的内在结构,那这就是无监督学习;如果我们想通过与环境交互来优化目标函数,这是强化学习。
- 根据输出结果分类:如果模型输出结果是一个数值,这是回归问题;如果输出结果是一个类别,这是分类问题;如果输出结果是一组输入数据,那这是聚类问题。
- 寻找可用的算法。
- 数据特征探索工程。或许比选择算法更重要的是正确选择表示数据的特征。虽然大多数特征的有效性需要靠实验来评估,但是了解常见的选取数据特征的方法是很有帮助的。这里有几个较好的方法:
- 主成分分析(PCA):一种线性降维方法,可以找出包含信息量较高的特征主成分,可以解释数据中的大多数方差。
- 尺度不变特征变换(SIFT):计算机视觉领域中的一种有专利的算法,用以检测和描述图片的局部特征。它有一个开源的替代方法 ORB(Oriented FAST and rotated BRIEF)。
- 加速稳健特征(SURF):SIFT 的更稳健版本,有专利。
- 方向梯度直方图(HOG):一种特征描述方法,在计算机视觉中用于计数一张图像中局部部分的梯度方向的 occurrence。
- 智能的特征选择
- 前向搜索:
- 最开始不选取任何特征。
- 然后选择最相关的特征,将这个特征加入到已有特征;计算模型的交叉验证误差,重复选取其它所有候选特征;最后,选取能使你交叉验证误差最小特征,并放入已选择的特征之中。
- 重复,直到达到期望数量的特征为止!
- 反向搜索:
- 从所有特征开始。
- 先移除最不相关的特征,然后计算模型的交叉验证误差;对其它所有候选特征,重复这一过程;最后,移除使交叉验证误差最大的候选特征。
- 重复,直到达到期望数量的特征为止!
- 实现所有适用的算法,模型选择。
- 对于任何给定的问题,通常有多种候选算法可以完成这项工作。那么我们如何知道选择哪一个呢?通常,这个问题的答案并不简单,所以我们必须反复试验。原型开发最好分两步完成。在第一步中,我们希望通过最小量的特征工程快速且粗糙地实现一些算法。在这个阶段,我们主要的目标是大概了解哪个算法表现得更好。
- 一旦我们将列表减少至几个候选算法,真正的原型开发开始了。理想情况下,我们会建立一个机器学习流程,使用一组经过仔细选择的评估标准来比较每个算法在数据集上的表现。
- 超参数优化。例如,主成分分析中的主成分个数,k 近邻算法的参数 k,或者是神经网络中的层数和学习速率。最好的方法是使用交叉验证来选择。
III. 学习方式
III.I. 离线学习与在线学习
机器学习算法可以分成两类。离线学习和在线学习。在线机器学习指每次通过一个训练实例学习模型的学习方法。
III.II. 主动学习与直推学习
III.II.I. 主动学习
主动学习(active learning),指的是这样一种学习方法:有的时候,有类标的数据比较稀少而没有类标的数据是相当丰富的,但是对数据进行人工标注又非常昂贵,这时候,学习算法可以主动地提出一些标注请求,将一些经过筛选的数据提交给专家进行标注。这个筛选过程也就是主动学习主要研究的地方了,怎么样筛选数据才能使得请求标注的次数尽量少而最终的结果又尽量好。
主动学习的过程大致是这样的,有一个已经标好类标的数据集K(初始时可能为空),和还没有标记的数据集U,通过K集合的信息,找出一个U的子集C,提出标注请求,待专家将数据集C标注完成后加入到K集合中,进行下一次迭代。
按wiki上所描述的看,主动学习也属于半监督学习的范畴了,但实际上是不一样的,半监督学习和直推学习(transductive learning)以及主动学习,都属于利用未标记数据的学习技术,但基本思想还是有区别的。
如上所述,主动学习的“主动”,指的是主动提出标注请求,也就是说,还是需要一个外在的能够对其请求进行标注的实体(通常就是相关领域人员),即主动学习是交互进行的。而半监督学习,特指的是学习算法不需要人工的干预,基于自身对未标记数据加以利用。
III.II.II. 直推学习
它与半监督学习一样不需要人工干预,不同的是,直推学习假设未标记的数据就是最终要用来测试的数据,学习的目的就是在这些数据上取得最佳泛化能力。相对应的,半监督学习在学习时并不知道最终的测试用例是什么。也就是说,直推学习其实类似于半监督学习的一个子问题,或者说是一个特殊化的半监督学习,所以也有人将其归为半监督学习。
III.III. 强化学习
所谓强化学习就是智能系统从环境到行为映射的学习,以使奖励信号(强化信号)函数值最大,强化学习不同于连接主义学习中的监督学习,主要表现在教师信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统RLS(reinforcement learning system)如何去产生正确的动作。由于外部环境提供的信息很少,RLS必须靠自身的经历进行学习。通过这种方式,RLS在行动-评价的环境中获得知识,改进行动方案以适应环境。
在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈 到模型,模型必须对此立刻作出调整。设计一个回报函数(reward function),如果learning agent(如上面的四足机器人、象棋AI程序)在决定一步后,获得了较好的结果,那么我们给agent一些回报(比如回报函数结果为正),得到较差的结果,那么回报函数为负。比如,四足机器人,如果他向前走了一步(接近目标),那么回报函数为正,后退为负。如果我们能够对每一步进行评价,得到相应的回报函数,那么就好办了,我们只需要找到一条回报值最大的路径(每步的回报之和最大),就认为是最佳的路径。
常见的应用场景包括动态系统以及机器人控制等。常见算法包括Q-Learning以及时间差学习(Temporal difference learning)
III.IV. 迁移学习
在传统的机器学习的框架下,学习的任务就是在给定充分训练数据的基础上来学习一个分类模型;然后利用这个学习到的模型来对测试文档进行分类与预测。然而,我们看到机器学习算法在当前的Web挖掘研究中存在着一个关键的问题:一些新出现的领域中的大量训练数据非常难得到。我们看到Web应用领域的发展非常快速。大量新的领域不断涌现,从传统的新闻,到网页,到图片,再到博客、播客等等。传统的机器学习需要对每个领域都标定大量训练数据,这将会耗费大量的人力与物力。而没有大量的标注数据,会使得很多与学习相关研究与应用无法开展。其次,传统的机器学习假设训练数据与测试数据服从相同的数据分布。然而,在许多情况下,这种同分布假设并不满足。通常可能发生的情况如训练数据过期。这往往需要我们去重新标注大量的训练数据以满足我们训练的需要,但标注新数据是非常昂贵的,需要大量的人力与物力。从另外一个角度上看,如果我们有了大量的、在不同分布下的训练数据,完全丢弃这些数据也是非常浪费的。如何合理的利用这些数据就是迁移学习主要解决的问题。迁移学习可以从现有的数据中迁移知识,用来帮助将来的学习。
迁移学习(Transfer Learning)的目标就是将从一个环境中学到的知识用来帮助新环境中的学习任务。因此,迁移学习不会像传统机器学习那样作同分布假设。举一个通俗的例子,一个会下象棋的人可以更容易的学会下围棋;一个认识桌子的人可以更加容易的认识椅子;
在迁移学习方面的工作目前可以分为以下三个部分:同构空间下基于实例的迁移学习,同构空间下基于特征的迁移学习与异构空间下的迁移学习。基于实例的迁移学习有更强的知识迁移能力,基于特征的迁移学习具有更广泛的知识迁移能力,而异构空间的迁移具有广泛的学习与扩展能力。
迁移学习即一种学习对另一种学习的影响,它广泛地存在于知识、技能、态度和行为规范的学习中。任何一种学习都要受到学习者已有知识经验、技能、态度等的影响,只要有学习,就有迁移。迁移是学习的继续和巩固,又是提高和深化学习的条件,学习与迁移不可分割。对于人工智能的发展路径,很多人可能对基于大数据的人工智能很熟悉,但其实还有基于小样本的尝试和迁移,这也是人工智能的一种路径。
IV. 实用建议
总结了机器学习研究者和从业者的宝贵经验34,其中包括需要避免的陷阱、值得关注的重点问题、常见问题的答案:
- 并非所有的问题都适合用机器学习解决(很多逻辑清晰的问题用规则能很高效和准确地处理),也没有一个机器学习算法可以通用于所有问题。从功能的角度分类,机器学习在一定量级的数据上,可以解决下列问题:分类、回归、聚类。
- 快速选择开发/测试集——如果有必要不要害怕更换。思考清理贴错标签的开发/测试集是否值得。考虑将开发集分为多个子集。
- 学习=表征+评估+优化。一个相关的问题是如何表征输入,即使用哪些特征。需要一个评估函数来区分分类器的好坏。我们要用一种方法搜索得分最高的分类器。
- 泛化能力很关键。
- 选择正确的评估指标。
- 仅有数据是不够的。机器学习并非魔术,它无法做到无中生有,它所做的是举一反三。
- 过拟合具有多面性。理解过拟合的一种方法是将泛化的误差进行分解,分为偏差和方差。除交叉验证之外,还有很多方法可以解决过拟合问题。最流行的是在评估函数中增加一个正则化项。
- 高维度会挫伤直觉。
- 理论保证与实际的出入。
- 特征工程是关键。
- 数据量为王。
- 不单单学习一个模型。
- 简单不意味着准确。
- 可表征并不意味着可学习。
- 相关性并不意味着因果关系。
- 机器学习是一个迭代过程:不要指望第一次就成功。快速构建第一个系统,然后迭代。并行评估多个想法。
V. 学习资源
The Who’s Who Of Machine Learning, And Why You Should Know Them
机器学习里所说的“算法”与程序员所说的“数据结构与算法分析”里的“算法”略有区别。前者更关注结果数据的召回率、精确度、准确性等方面,后者更关注执行过程的时间复杂度、空间复杂度等方面。 当然,实际机器学习问题中,对效率和资源占用的考量是不可或缺的。
『数学基础』『典型机器学习算法』『编程基础』三个并行的部分,是因为机器学习是一个将数学/算法理论和工程实践紧密结合的领域,需要扎实的理论基础帮助引导数据分析与模型调优,同时也需要精湛的工程开发能力去高效化地训练和部署模型和服务。(每一个算法,要在训练集上最大程度拟合同时又保证泛化能力,需要不断分析结果和数据,调优参数,这需要我们对数据分布和模型底层的数学原理有一定的理解。)。具备了机器学习的必要条件,剩下的就是怎么运用它们去做一个完整的机器学习项目。其工作流程如下: 抽象成数学问题—— 获取数据——特征预处理与特征选择——训练模型与调优——模型诊断——模型融合——上线运行。
入门系列:
- 读懂机器学习需要哪些数学知识
- 机器学习 新手快速入门 Getting Started With MachineLearning (all in one).pdf
- Andrew Ng(中文名:吴恩达)自2002年获得博士学位以来,Andrew Ng一直在斯坦福任教。他创建并领导了谷歌大脑团队,该团队被认为是世界上最先进的ML/AI研究机构之一。
- My First Step Into Machine Learning。
- Andrew Ng所拍摄的《深度学习的英雄》(the heroes of deeplearning)的采访列表。
- 吴恩达的新书Machine Learning Yearning,是Ng在机器学习工程实践中的经验总结,非常实用且独一无二的一本书,短小精悍但干货十足,强烈推荐给从事数据领域的团队与个人。
- Geoffrey Hinton被称为AI教父,是神经网络领域的首批研究者之一。当他是卡内基梅隆大学的教授时,他是最早证明广义反向传播算法的研究者之一。在Andrew Ng的引导下,他在coursera上发布了他的神经网络课程,这是一个巨大的成功。
- 2014年,Ian Goodfellow发表了一篇关于GANs的论文,这是AI行业的一个突破。GANs基本上允许计算机进行想象,计算机可以训练与我们提供给它的模型相似的模型。
- Yann LeCun发明了卷积神经网络,如果没有他的贡献,图像识别领域就不会有进展。关于人工智能未来的一个有趣的演讲。
个人博客系列:
- Data Science and Robots-Brandon Rohrer
- 2018年3月1日,Google上线了AI学习网站——Learn with Google AI,并重磅推出了机器学习速成课程MLCC,该课程基于TensorFlow(TF),旨在为所有经验水平的人提供免费课程、教程和动手练习。
- Mining of Massive Datasets,Social Media Mining,
- Awesome Data Science(清单),Scikit-Learn Tutorial: Statistical-Learning for Scientific Data Processing
- Think Bayes,Machine Learning and Big Data,Statistical Learning with Sparsity,Statistical inference for data science,Convex Optimization,
- Understanding MachineLearning: From Theory to Algorithms
- Awesome Artificial Intelligence (AI)(清单)
- Awesome-machine-learning (清单)。Machine Learning (An Algorithmic Perspective)
- Neural Networks and Deep Learning,Deep Learning Deep Learning Tutorial
- Awesome Reinforcement Learning来自于aikorea整理的一份关于强化学习的代码、论文、应用、教程的清单。
- An Introduction to Statistical Learning (with applications in R)
- Python Data Science Handbook,Building Machine Learning Systems with Python,Natural Language Processing with Python,Automate the Boring Stuff with Python,
VI. 数据集
部分网址需要科学上网配置。
- List of datasets for machine learning research
- UCI Machine Learning Repository: Data Sets是网络上最早的数据集来源之一,是寻找各种有趣数据集的第一选择。
- Comp-Engine Time Series
- Datasets | Kaggle是由联合创始人、首席执行官安东尼·高德布卢姆(Anthony Goldbloom)2010年在墨尔本创立的,主要为开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的平台。该平台已经吸引了80万名数据科学家的关注。
- Data.gov
- 17 Free Data Science Projects To Boost Your Knowledge & Skills
- 数据堂
- Prognostics Center of Excellence - Data Repository
- LIBSVM Data: Regression
- Regression Data Sets
- Environmental and Industrial Machine Learning Group
- KEEL: A software tool to assess evolutionary algorithms for Data Mining problems (regression, classification, clustering, pattern mining and so on)
- Sunspot Number | SILSO
- Met Office Hadley Centre observations datasets
- Energy Consumption Database
- Time Series Data Library - Data provider — DataMarket
- Time Series Data | International Institute of Forecasters
- neural-forecasting-competition
- Browse time-series data by category - Comp-Engine Time Series
- PhysioBank Databases